 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHCHS-30 : A Free Chinese Speech Corpus
Paper and Code

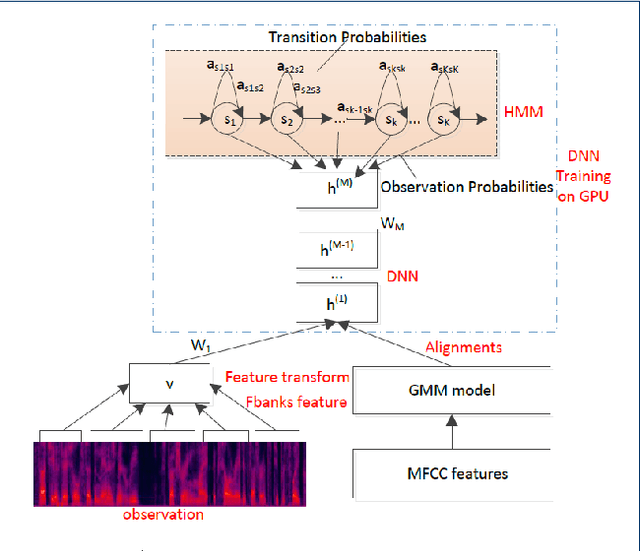

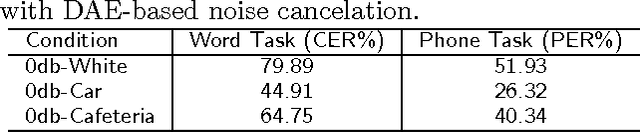
Speech data is crucially important for speech recognition research. There are quite some speech databases that can be purchased at prices that are reasonable for most research institutes. However, for young people who just start research activities or those who just gain initial interest in this direction, the cost for data is still an annoying barrier. We support the `free data' movement in speech recognition: research institutes (particularly supported by public funds) publish their data freely so that new researchers can obtain sufficient data to kick of their career. In this paper, we follow this trend and release a free Chinese speech database THCHS-30 that can be used to build a full- edged Chinese speech recognition system. We report the baseline system established with this database, including the performance under highly noisy conditions.