 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-Mamba: A Time-Frequency Network for Sound Source Localization
Paper and Code
Sep 08, 2024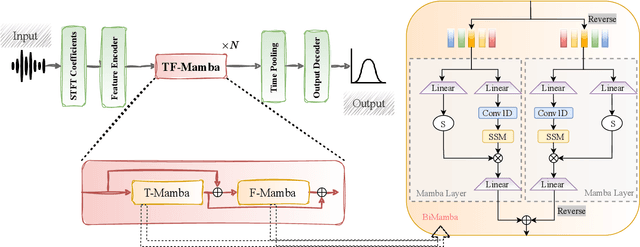
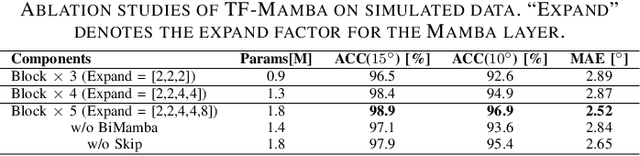

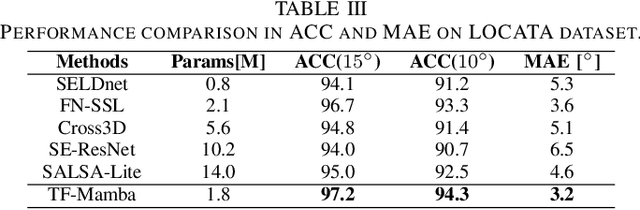
Sound source localization (SSL) determines the position of sound sources using multi-channel audio data. It is commonly used to improve speech enhancement and separation. Extracting spatial features is crucial for SSL, especially in challenging acoustic environments. Previous studies performed well based on long short-term memory models. Recently, a novel scalable SSM referred to as Mamba demonstrated notable performance across various sequence-based modalities, including audio and speech. This study introduces the Mamba for SSL tasks. We consider the Mamba-based model to analyze spatial features from speech signals by fusing both time and frequency features, and we develop an SSL system called TF-Mamba. This system integrates time and frequency fusion, with Bidirectional Mamba managing both time-wise and frequency-wise processing. We conduct the experiments on the simulated dataset and the LOCATA dataset. Experiments show that TF-Mamba significantly outperforms other advanced methods on simulated and real-world data.