 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-To-Speech Data Augmentation for Low Resource Speech Recognition
Paper and Code
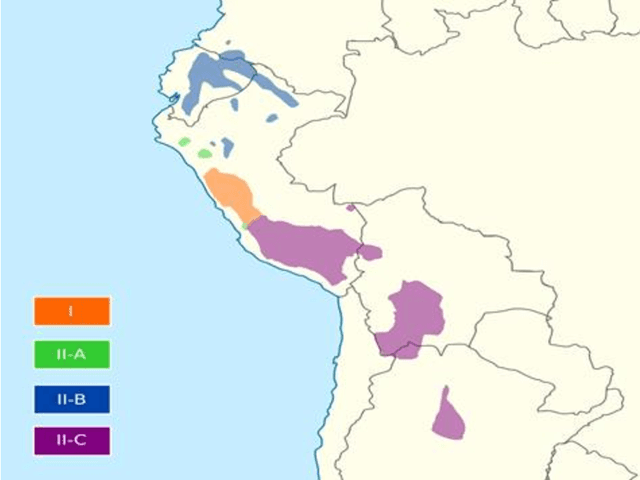
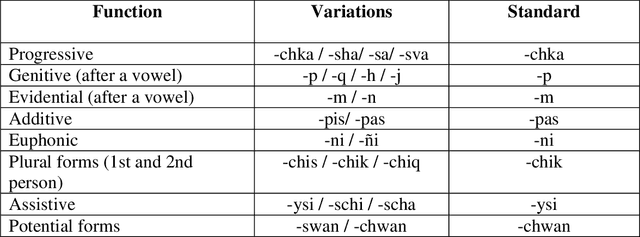
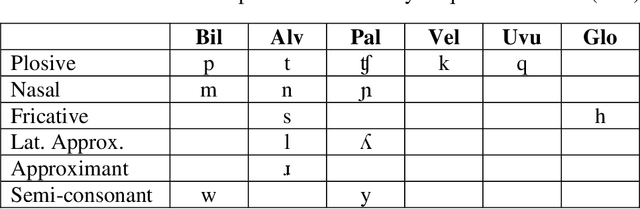
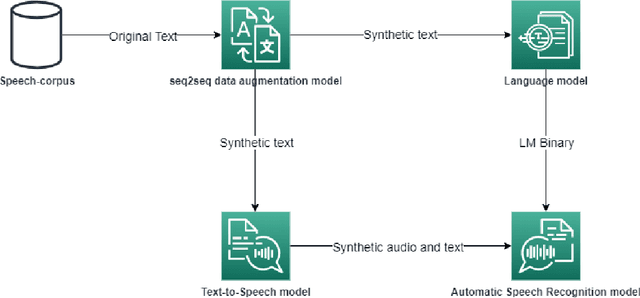
Nowadays, the main problem of deep learning techniques used in the development of automatic speech recognition (ASR) models is the lack of transcribed data. The goal of this research is to propose a new data augmentation method to improve ASR models for agglutinative and low-resource languages. This novel data augmentation method generates both synthetic text and synthetic audio. Some experiments were conducted using the corpus of the Quechua language, which is an agglutinative and low-resource language. In this study, a sequence-to-sequence (seq2seq) model was applied to generate synthetic text, in addition to generating synthetic speech using a text-to-speech (TTS) model for Quechua. The results show that the new data augmentation method works well to improve the ASR model for Quechua. In this research, an 8.73% improvement in the word-error-rate (WER) of the ASR model is obtained using a combination of synthetic text and synthetic speech.