 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Segmentation Using Exponential Models
Paper and Code
Jun 13, 1997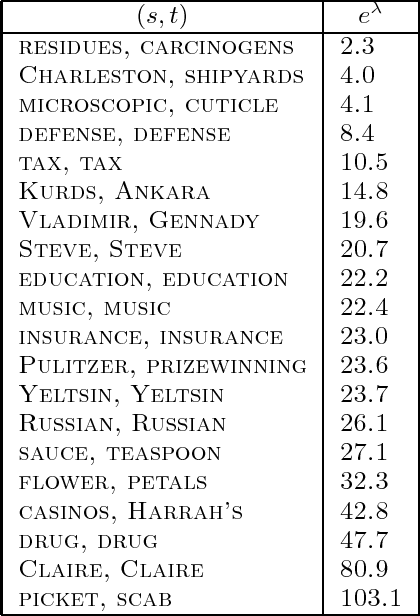
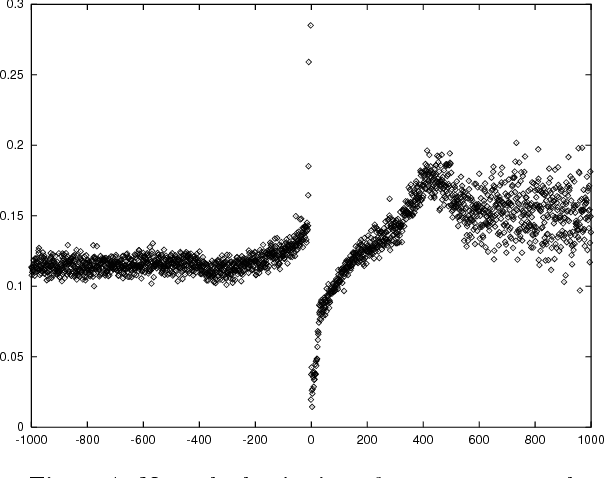
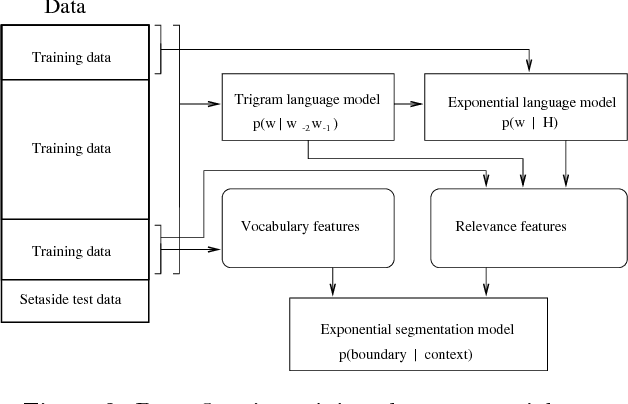
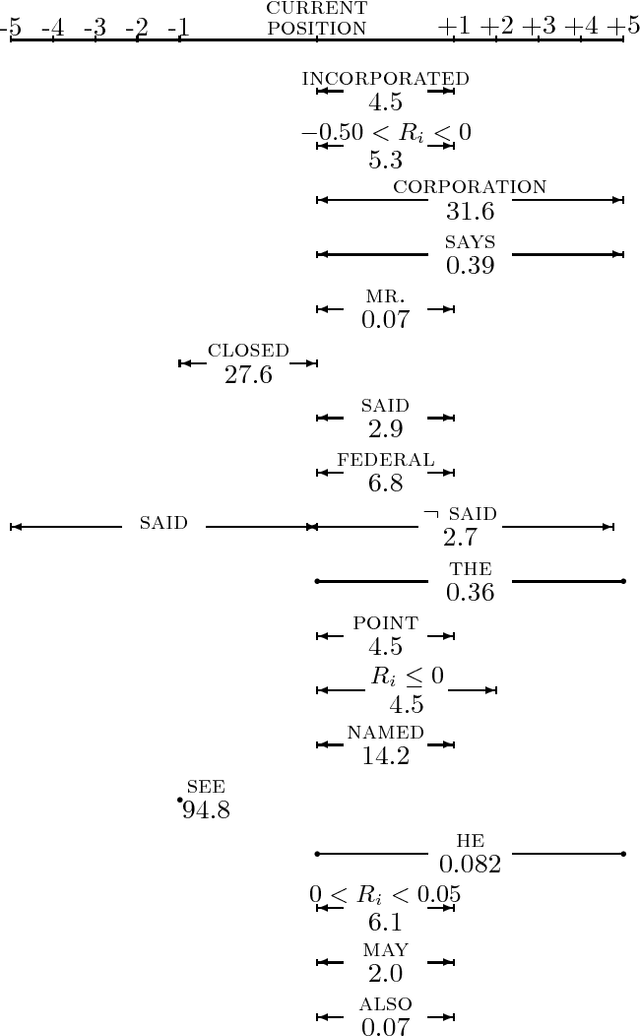
This paper introduces a new statistical approach to partitioning text automatically into coherent segments. Our approach enlists both short-range and long-range language models to help it sniff out likely sites of topic changes in text. To aid its search, the system consults a set of simple lexical hints it has learned to associate with the presence of boundaries through inspection of a large corpus of annotated data. We also propose a new probabilistically motivated error metric for use by the natural language processing and information retrieval communities, intended to supersede precision and recall for appraising segmentation algorithms. Qualitative assessment of our algorithm as well as evaluation using this new metric demonstrate the effectiveness of our approach in two very different domains, Wall Street Journal articles and the TDT Corpus, a collection of newswire articles and broadcast news transcripts.