 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the limits of unsupervised learning for semantic similarity
Paper and Code
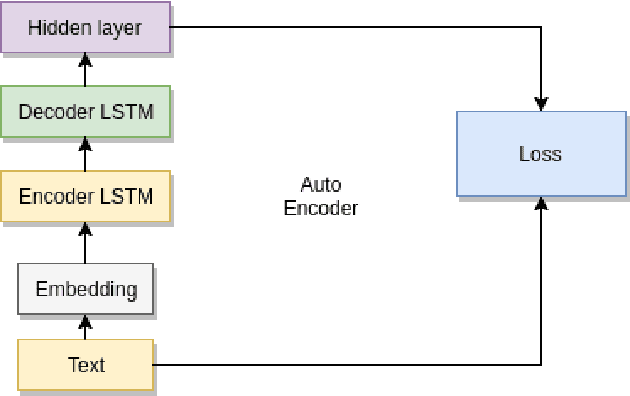
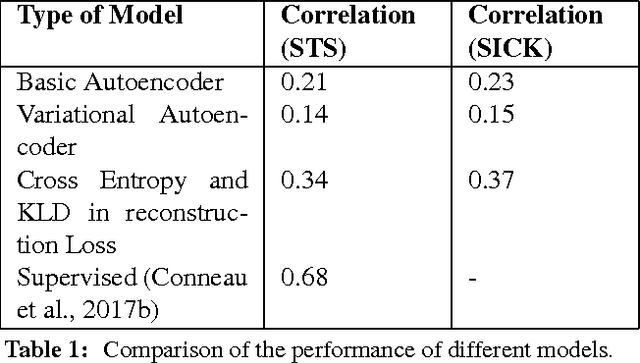
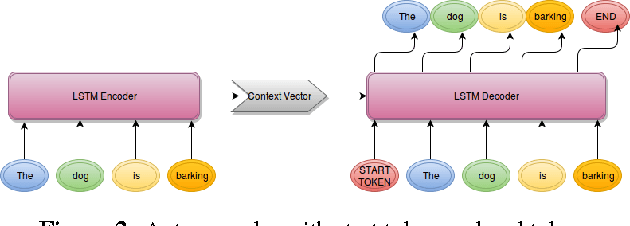
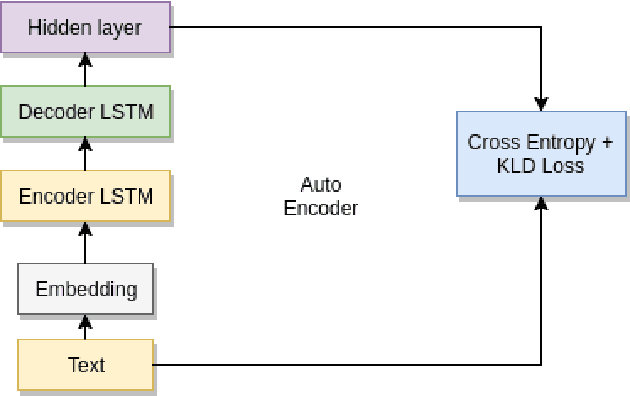
Semantic Similarity between two sentences can be defined as a way to determine how related or unrelated two sentences are. The task of Semantic Similarity in terms of distributed representations can be thought to be generating sentence embeddings (dense vectors) which take both context and meaning of sentence in account. Such embeddings can be produced by multiple methods, in this paper we try to evaluate LSTM auto encoders for generating these embeddings. Unsupervised algorithms (auto encoders to be specific) just try to recreate their inputs, but they can be forced to learn order (and some inherent meaning to some extent) by creating proper bottlenecks. We try to evaluate how properly can algorithms trained just on plain English Sentences learn to figure out Semantic Similarity, without giving them any sense of what meaning of a sentence is.