 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting distributional assumptions of learning algorithms
Paper and Code
Apr 14, 2022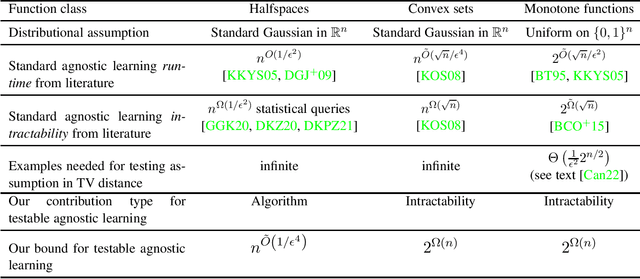
There are many important high dimensional function classes that have fast agnostic learning algorithms when strong assumptions on the distribution of examples can be made, such as Gaussianity or uniformity over the domain. But how can one be sufficiently confident that the data indeed satisfies the distributional assumption, so that one can trust in the output quality of the agnostic learning algorithm? We propose a model by which to systematically study the design of tester-learner pairs $(\mathcal{A},\mathcal{T})$, such that if the distribution on examples in the data passes the tester $\mathcal{T}$ then one can safely trust the output of the agnostic learner $\mathcal{A}$ on the data. To demonstrate the power of the model, we apply it to the classical problem of agnostically learning halfspaces under the standard Gaussian distribution and present a tester-learner pair with a combined run-time of $n^{\tilde{O}(1/\epsilon^4)}$. This qualitatively matches that of the best known ordinary agnostic learning algorithms for this task. In contrast, finite sample Gaussian distribution testers do not exist for the $L_1$ and EMD distance measures. A key step in the analysis is a novel characterization of concentration and anti-concentration properties of a distribution whose low-degree moments approximately match those of a Gaussian. We also use tools from polynomial approximation theory. In contrast, we show strong lower bounds on the combined run-times of tester-learner pairs for the problems of agnostically learning convex sets under the Gaussian distribution and for monotone Boolean functions under the uniform distribution over $\{0,1\}^n$. Through these lower bounds we exhibit natural problems where there is a dramatic gap between standard agnostic learning run-time and the run-time of the best tester-learner pair.