 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Switching Networks
Paper and Code


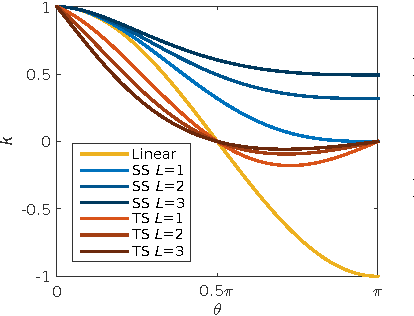
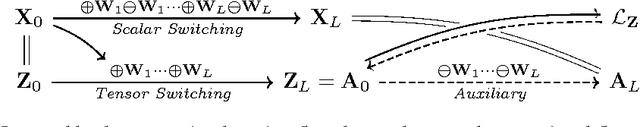
We present a novel neural network algorithm, the Tensor Switching (TS) network, which generalizes the Rectified Linear Unit (ReLU) nonlinearity to tensor-valued hidden units. The TS network copies its entire input vector to different locations in an expanded representation, with the location determined by its hidden unit activity. In this way, even a simple linear readout from the TS representation can implement a highly expressive deep-network-like function. The TS network hence avoids the vanishing gradient problem by construction, at the cost of larger representation size. We develop several methods to train the TS network, including equivalent kernels for infinitely wide and deep TS networks, a one-pass linear learning algorithm, and two backpropagation-inspired representation learning algorithms. Our experimental results demonstrate that the TS network is indeed more expressive and consistently learns faster than standard ReLU networks.