 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Coherent Embeddings for Self-Supervised Video Representation Learning
Paper and Code
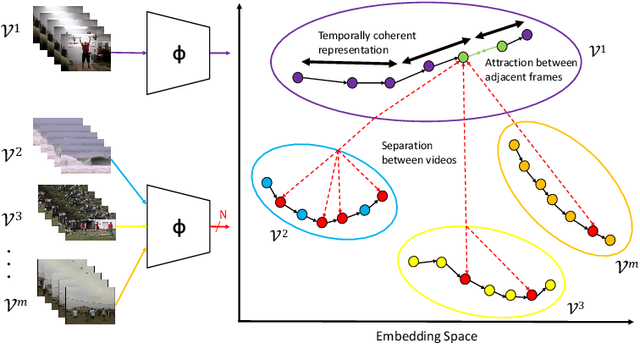
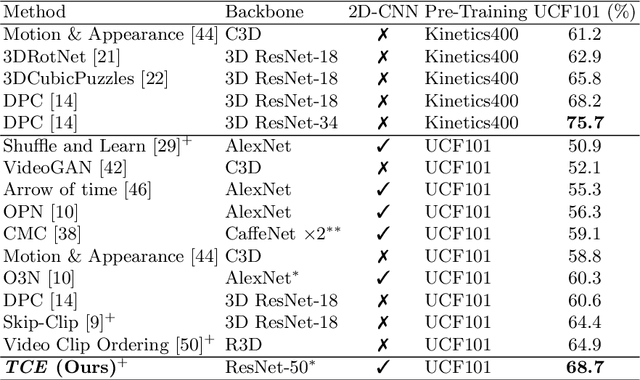
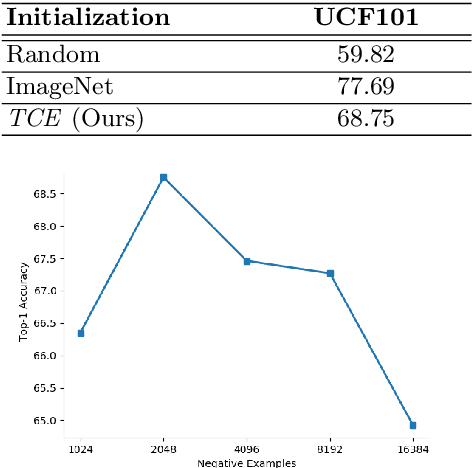
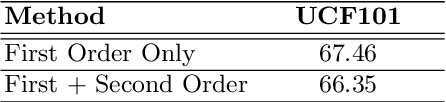
This paper presents TCE: Temporally Coherent Embeddings for self-supervised video representation learning. The proposed method exploits inherent structure of unlabeled video data to explicitly enforce temporal coherency in the embedding space, rather than indirectly learning it through ranking or predictive pretext tasks. In the same way that high-level visual information in the world changes smoothly, we believe that nearby frames in learned representations should demonstrate similar properties. Using this assumption, we train the TCE model to encode videos such that adjacent frames exist close to each other and videos are separated from one another. Using TCE we learn robust representations from large quantities of unlabeled video data. We evaluate our self-supervised trained TCE model by adding a classification layer and finetuning the learned representation on the downstream task of video action recognition on the UCF101 dataset. We obtain 67.01% accuracy and outperform the state-of-the-art self-supervised methods trained on UCF101 despite using a significantly smaller dataset for pre-training. Notably, we demonstrate results competitive with more complex 3D-CNN based networks while training with a 2D-CNN network backbone on action recognition tasks. Our training code and pretrained models are available at https://github.com/csiro-robotics/TCE