Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Analysis of Language through Neural Language Models
Paper and Code
May 14, 2014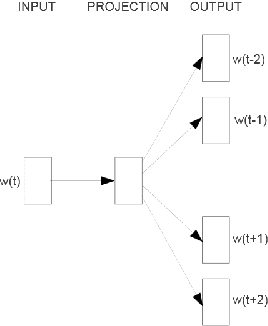
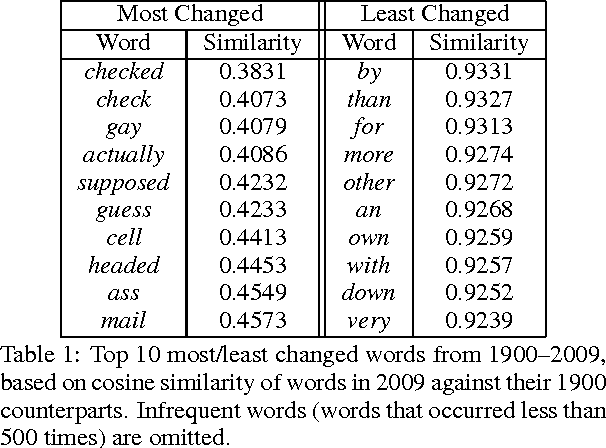

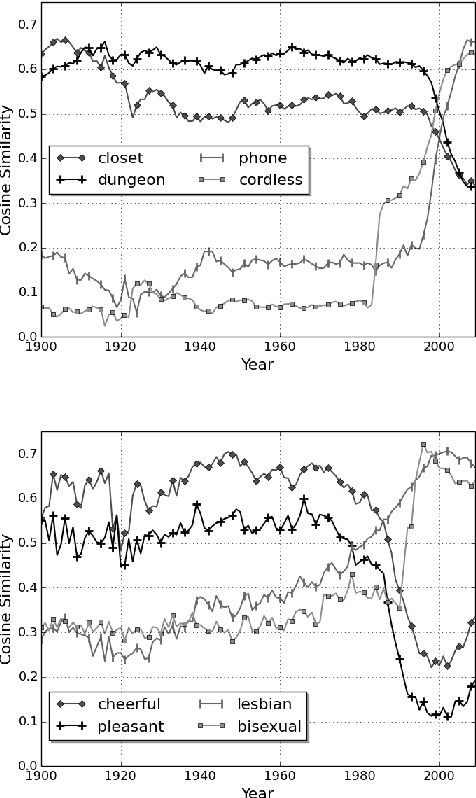
We provide a method for automatically detecting change in language across time through a chronologically trained neural language model. We train the model on the Google Books Ngram corpus to obtain word vector representations specific to each year, and identify words that have changed significantly from 1900 to 2009. The model identifies words such as "cell" and "gay" as having changed during that time period. The model simultaneously identifies the specific years during which such words underwent change.
* Proceedings of the ACL 2014 Workshop on Language Technologies and
Computational Social Science. June, 2014. 61--65
View paper on