 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleoperator Imitation with Continuous-time Safety
Paper and Code
May 23, 2019

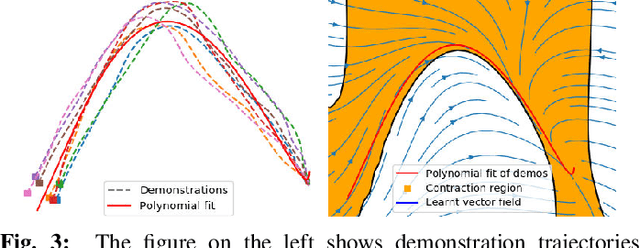
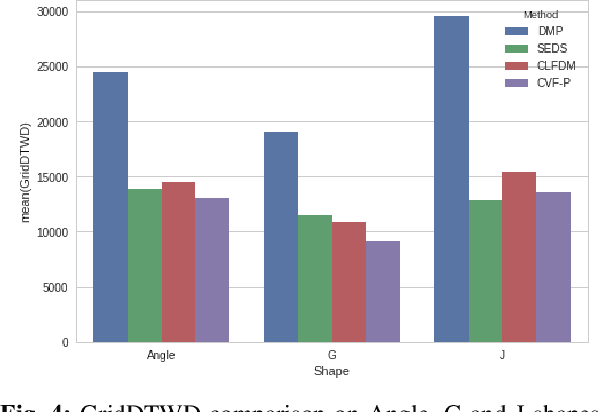
Learning to effectively imitate human teleoperators, with generalization to unseen and dynamic environments, is a promising path to greater autonomy enabling robots to steadily acquire complex skills from supervision. We propose a new motion learning technique rooted in contraction theory and sum-of-squares programming for estimating a control law in the form of a polynomial vector field from a given set of demonstrations. Notably, this vector field is provably optimal for the problem of minimizing imitation loss while providing continuous-time guarantees on the induced imitation behavior. Our method generalizes to new initial and goal poses of the robot and can adapt in real-time to dynamic obstacles during execution, with convergence to teleoperator behavior within a well-defined safety tube. We present an application of our framework for pick-and-place tasks in the presence of moving obstacles on a 7-DOF KUKA IIWA arm. The method compares favorably to other learning-from-demonstration approaches on benchmark handwriting imitation tasks.