Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Me to Explain: A Review of Datasets for Explainable NLP
Paper and Code
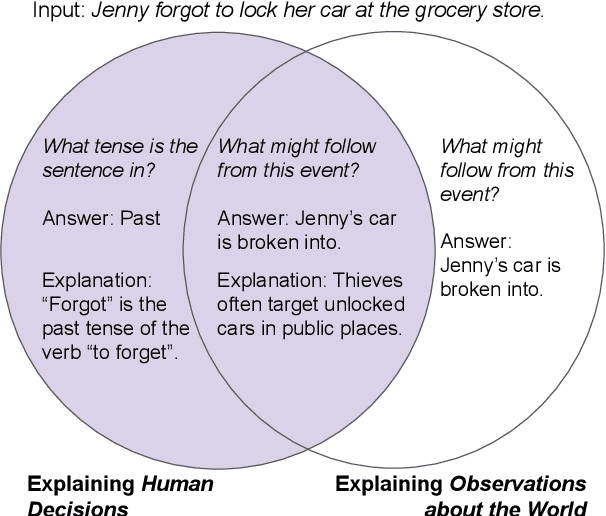
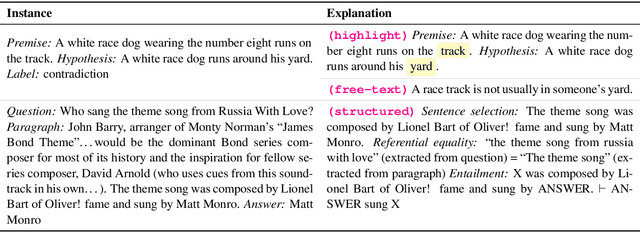

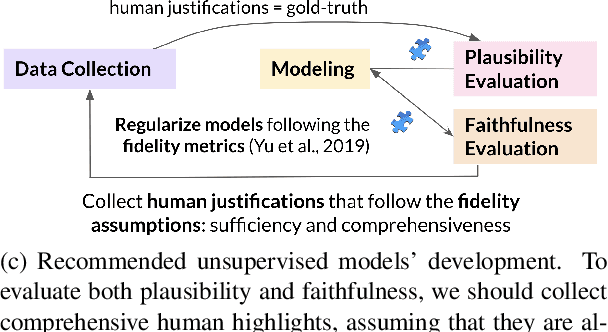
Explainable NLP (ExNLP) has increasingly focused on collecting human-annotated explanations. These explanations are used downstream in three ways: as data augmentation to improve performance on a predictive task, as a loss signal to train models to produce explanations for their predictions, and as a means to evaluate the quality of model-generated explanations. In this review, we identify three predominant classes of explanations (highlights, free-text, and structured), organize the literature on annotating each type, point to what has been learned to date, and give recommendations for collecting ExNLP datasets in the future.
* Version 2: added missing references, changed the NLI example in Table
1, and corrected typos
View paper on