 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDSM: Triplet Diffusion for Skeleton-Text Matching in Zero-Shot Action Recognition
Paper and Code
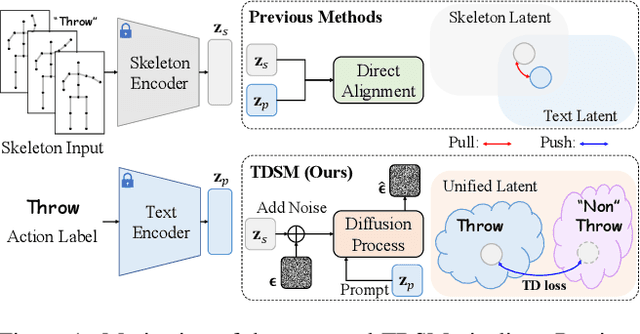
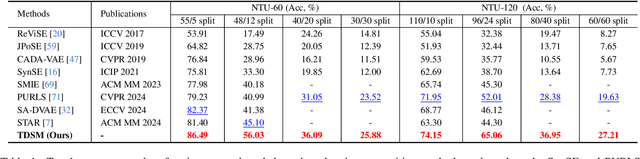
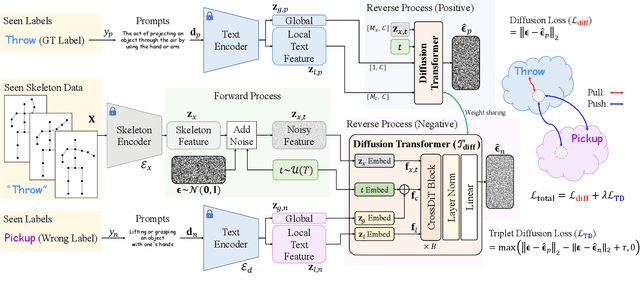
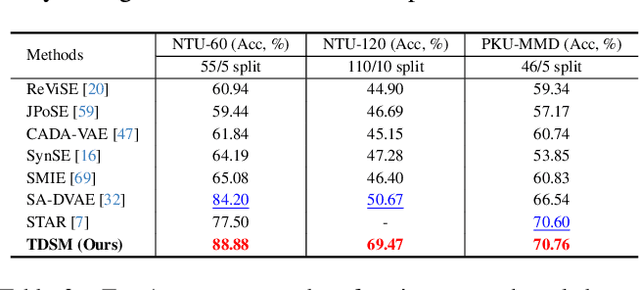
We firstly present a diffusion-based action recognition with zero-shot learning for skeleton inputs. In zero-shot skeleton-based action recognition, aligning skeleton features with the text features of action labels is essential for accurately predicting unseen actions. Previous methods focus on direct alignment between skeleton and text latent spaces, but the modality gaps between these spaces hinder robust generalization learning. Motivated from the remarkable performance of text-to-image diffusion models, we leverage their alignment capabilities between different modalities mostly by focusing on the training process during reverse diffusion rather than using their generative power. Based on this, our framework is designed as a Triplet Diffusion for Skeleton-Text Matching (TDSM) method which aligns skeleton features with text prompts through reverse diffusion, embedding the prompts into the unified skeleton-text latent space to achieve robust matching. To enhance discriminative power, we introduce a novel triplet diffusion (TD) loss that encourages our TDSM to correct skeleton-text matches while pushing apart incorrect ones. Our TDSM significantly outperforms the very recent state-of-the-art methods with large margins of 2.36%-point to 13.05%-point, demonstrating superior accuracy and scalability in zero-shot settings through effective skeleton-text matching.