 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-Net: Triple Context Network for Automated Stroke Lesion Segmentation
Paper and Code
Feb 28, 2022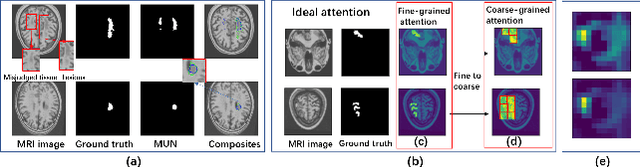
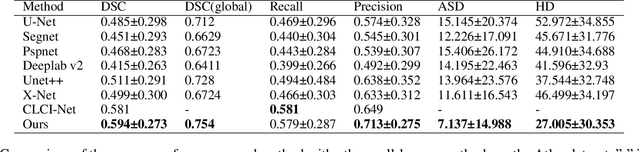
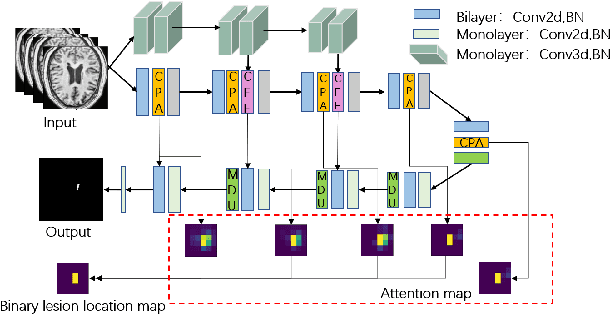

Accurate lesion segmentation plays a key role in the clinical mapping of stroke. Convolutional neural network (CNN) approaches based on U-shaped structures have achieved remarkable performance in this task. However, the single-stage encoder-decoder unresolvable the inter-class similarity due to the inadequate utilization of contextual information, such as lesion-tissue similarity. In addition, most approaches use fine-grained spatial attention to capture spatial context information, yet fail to generate accurate attention maps in encoding stage and lack effective regularization. In this work, we propose a new network, Triple Context Network (TC-Net), with the capture of spatial contextual information as the core. We firstly design a coarse-grained patch attention module to generate patch-level attention maps in the encoding stage to distinguish targets from patches and learn target-specific detail features. Then, to enrich the representation of boundary information of these features, a cross-feature fusion module with global contextual information is explored to guide the selective aggregation of 2D and 3D feature maps, which compensates for the lack of boundary learning capability of 2D convolution. Finally, we use multi-scale deconvolution instead of linear interpolation to enhance the recovery of target space and boundary information in the decoding stage. Our network is evaluated on the open dataset ATLAS, achieving the highest DSC score of 0.594, Hausdorff distance of 27.005 mm, and average symmetry surface distance of 7.137 mm, where our proposed method outperforms other state-of-the-art methods.