 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Multi-User Semantic Communications for Multimodal Data
Paper and Code
Aug 16, 2021

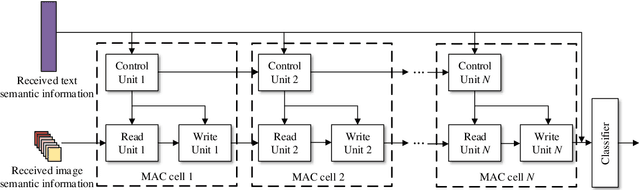
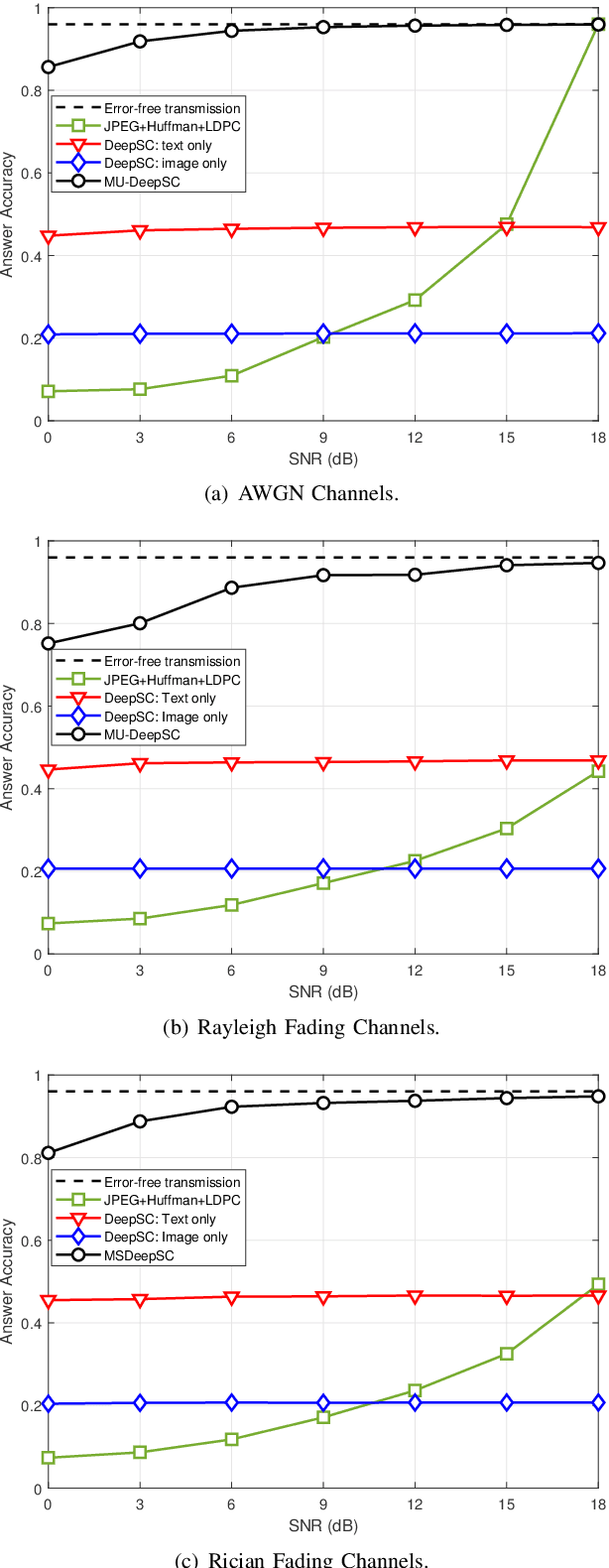
Semantic communications focus on the successful transmission of information relevant to the transmission task. In this paper, we investigate multi-users transmission for multimodal data in a task semantic communication system. We take the vision-answering as the semantic transmission task, in which part of the users transmit images and the other users transmit text to inquiry the information about the images. The receiver will provide answers based on the image and text from multiple users in the considered system. To exploit the correlation between the multimodal data from multiple users, we proposed a deep neural network enabled multi-user semantic communication system, named MU-DeepSC, for the visual question answering (VQA) task, in which the answer is highly dependent on the related image and text from the multiple users. Particularly, based on the memory, attention, and composition (MAC) neural network, we jointly design the transceiver and merge the MAC network to capture the features from the correlated multimodal data for serving the transmission task. The MU-DeepSC extracts the semantic information of image and text from different users and then generates the corresponding answers. Simulation results validate the feasibility of the proposed MU-DeepSC, which is more robust to various channel conditions than the traditional communication systems, especially in the low signal-to-noise (SNR) regime.