 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASAC: Temporally Abstract Soft Actor-Critic for Continuous Control
Paper and Code
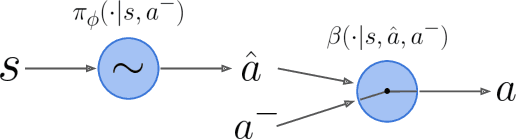

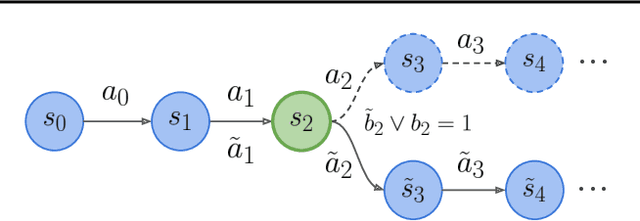

We propose temporally abstract soft actor-critic (TASAC), an off-policy RL algorithm that incorporates closed-loop temporal abstraction into the soft actor-critic (SAC) framework in a simple manner. TASAC adds a second-stage binary policy to choose between the previous action and the action output by an SAC actor. It has two benefits compared to traditional off-policy RL algorithms: persistent exploration and an unbiased multi-step Q operator for TD learning. We demonstrate its advantages over several strong baselines across 5 different categories of 14 continuous control tasks, in terms of both sample efficiency and final performance. Because of its simplicity and generality, TASAC can serve as a drop-in replacement for SAC when temporal abstraction is needed.