 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamizhi-Net OCR: Creating A Quality Large Scale Tamil-Sinhala-English Parallel Corpus Using Deep Learning Based Printed Character Recognition
Paper and Code


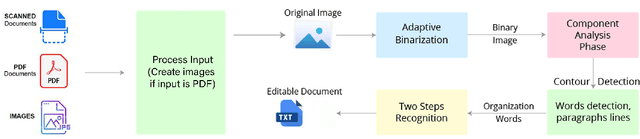
Most of the low resource languages do not have the necessary resources to create even a substantial monolingual corpus. These languages may often be found in government proceedings but mostly in the form of Portable Document Formats (PDFs) that contains legacy fonts. Extracting text from these documents to create a monolingual corpus is challenging due to legacy font usage and printer-friendly encoding which are not optimized for text extraction. Therefore, we propose a simple, automatic, and novel idea that can scale for Tamil, Sinhala, and English languages and many documents. For this purpose, we enhanced the performance of Tesseract 4.1.1 by employing LSTM-based training on many legacy fonts to recognize printed characters in the above languages. Especially, our model detects code-mix text, numbers, and special characters from the printed document. It is shown that this approach can boost the character-level accuracy of Tesseract 4.1.1 from 85.5 to 98.2 for Tamil (+12.9% relative change) and 91.8 to 94.8 for Sinhala (+3.26% relative change) on a dataset that is considered as challenging by its authors.