Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking-Heads Attention
Paper and Code
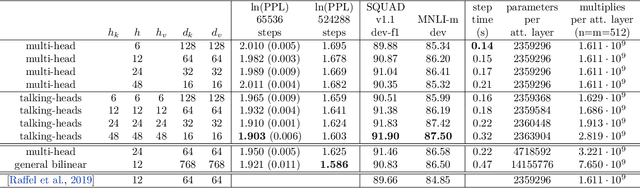


We introduce "talking-heads attention" - a variation on multi-head attention which includes linearprojections across the attention-heads dimension, immediately before and after the softmax operation.While inserting only a small number of additional parameters and a moderate amount of additionalcomputation, talking-heads attention leads to better perplexities on masked language modeling tasks, aswell as better quality when transfer-learning to language comprehension and question answering tasks.
View paper on