 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking Face Generation by Conditional Recurrent Adversarial Network
Paper and Code
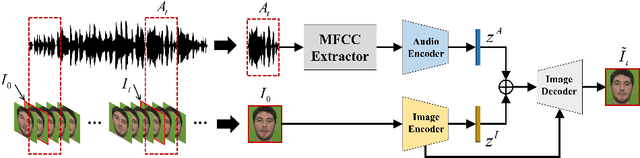
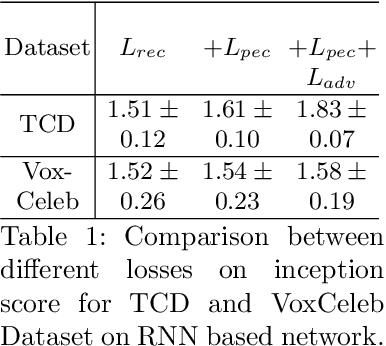


Given an arbitrary face image and an arbitrary speech clip, the proposed work attempts to generating the talking face video with accurate lip synchronization while maintaining smooth transition of both lip and facial movement over the entire video clip. Existing works either do not consider temporal dependency on face images across different video frames thus easily yielding noticeable/abrupt facial and lip movement or are only limited to the generation of talking face video for a specific person thus lacking generalization capacity. We propose a novel conditional video generation network where the audio input is treated as a condition for the recurrent adversarial network such that temporal dependency is incorporated to realize smooth transition for the lip and facial movement. In addition, we deploy a multi-task adversarial training scheme in the context of video generation to improve both photo-realism and the accuracy for lip synchronization. Finally, based on the phoneme distribution information extracted from the audio clip, we develop a sample selection method that effectively reduces the size of the training dataset without sacrificing the quality of the generated video. Extensive experiments on both controlled and uncontrolled datasets demonstrate the superiority of the proposed approach in terms of visual quality, lip sync accuracy, and smooth transition of lip and facial movement, as compared to the state-of-the-art.