 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaiwan LLM: Bridging the Linguistic Divide with a Culturally Aligned Language Model
Paper and Code


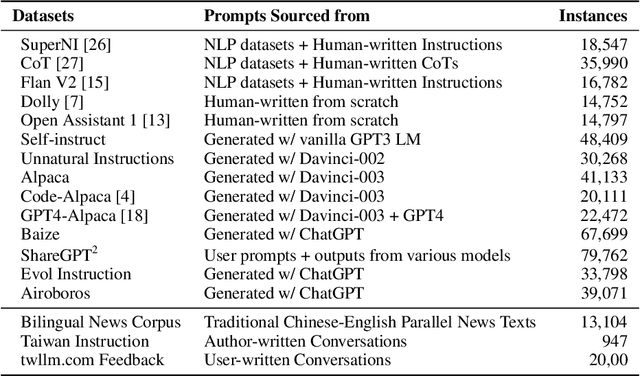

In the realm of language models, the nuanced linguistic and cultural intricacies of Traditional Chinese, as spoken in Taiwan, have been largely overlooked. This paper introduces Taiwan LLM, a pioneering Large Language Model that specifically caters to the Traditional Chinese language, with a focus on the variant used in Taiwan. Leveraging a comprehensive pretraining corpus and instruction-finetuning datasets, we have developed a model that not only understands the complexities of Traditional Chinese but also embodies the cultural context of Taiwan. Taiwan LLM represents the first of its kind, a model that is not only linguistically accurate but also culturally resonant with its user base. Our evaluations demonstrate that Taiwan LLM achieves superior performance in understanding and generating Traditional Chinese text, outperforming existing models that are predominantly trained on Simplified Chinese or English. The open-source release of Taiwan LLM invites collaboration and further innovation, ensuring that the linguistic diversity of Chinese speakers is embraced and well-served. The model, datasets, and further resources are made publicly available to foster ongoing research and development in this field.