 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data as Validation
Paper and Code
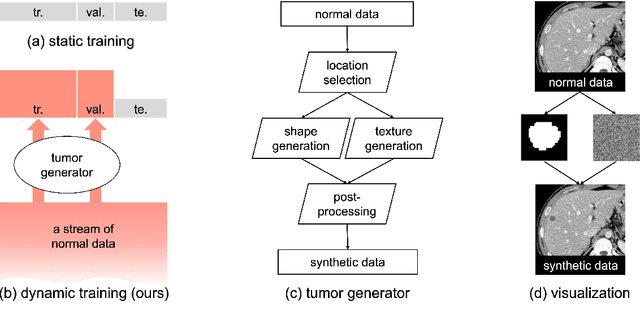
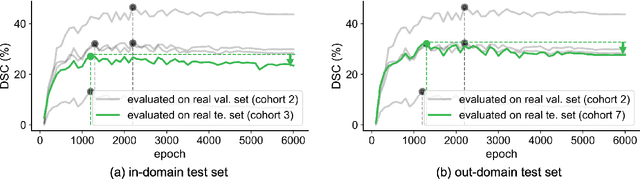

This study leverages synthetic data as a validation set to reduce overfitting and ease the selection of the best model in AI development. While synthetic data have been used for augmenting the training set, we find that synthetic data can also significantly diversify the validation set, offering marked advantages in domains like healthcare, where data are typically limited, sensitive, and from out-domain sources (i.e., hospitals). In this study, we illustrate the effectiveness of synthetic data for early cancer detection in computed tomography (CT) volumes, where synthetic tumors are generated and superimposed onto healthy organs, thereby creating an extensive dataset for rigorous validation. Using synthetic data as validation can improve AI robustness in both in-domain and out-domain test sets. Furthermore, we establish a new continual learning framework that continuously trains AI models on a stream of out-domain data with synthetic tumors. The AI model trained and validated in dynamically expanding synthetic data can consistently outperform models trained and validated exclusively on real-world data. Specifically, the DSC score for liver tumor segmentation improves from 26.7% (95% CI: 22.6%-30.9%) to 34.5% (30.8%-38.2%) when evaluated on an in-domain dataset and from 31.1% (26.0%-36.2%) to 35.4% (32.1%-38.7%) on an out-domain dataset. Importantly, the performance gain is particularly significant in identifying very tiny liver tumors (radius < 5mm) in CT volumes, with Sensitivity improving from 33.1% to 55.4% on an in-domain dataset and 33.9% to 52.3% on an out-domain dataset, justifying the efficacy in early detection of cancer. The application of synthetic data, from both training and validation perspectives, underlines a promising avenue to enhance AI robustness when dealing with data from varying domains.