 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic and Real Inputs for Tool Segmentation in Robotic Surgery
Paper and Code
Jul 26, 2020
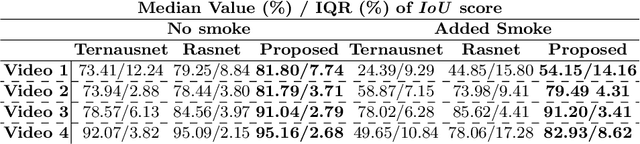

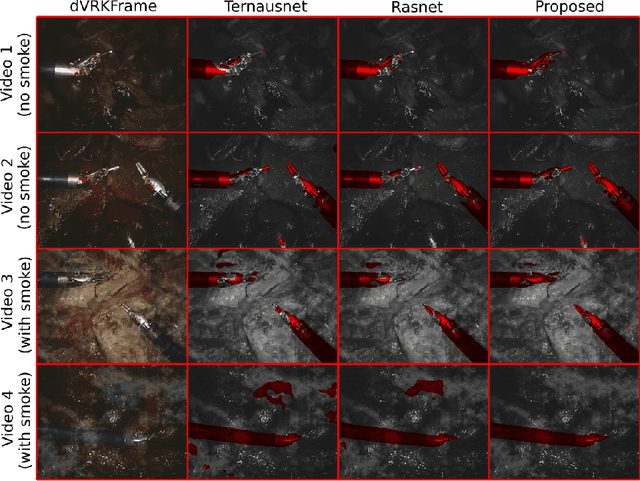
Semantic tool segmentation in surgical videos is important for surgical scene understanding and computer-assisted interventions as well as for the development of robotic automation. The problem is challenging because different illumination conditions, bleeding, smoke and occlusions can reduce algorithm robustness. At present labelled data for training deep learning models is still lacking for semantic surgical instrument segmentation and in this paper we show that it may be possible to use robot kinematic data coupled with laparoscopic images to alleviate the labelling problem. We propose a new deep learning based model for parallel processing of both laparoscopic and simulation images for robust segmentation of surgical tools. Due to the lack of laparoscopic frames annotated with both segmentation ground truth and kinematic information a new custom dataset was generated using the da Vinci Research Kit (dVRK) and is made available.