 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival Kernets: Scalable and Interpretable Deep Kernel Survival Analysis with an Accuracy Guarantee
Paper and Code
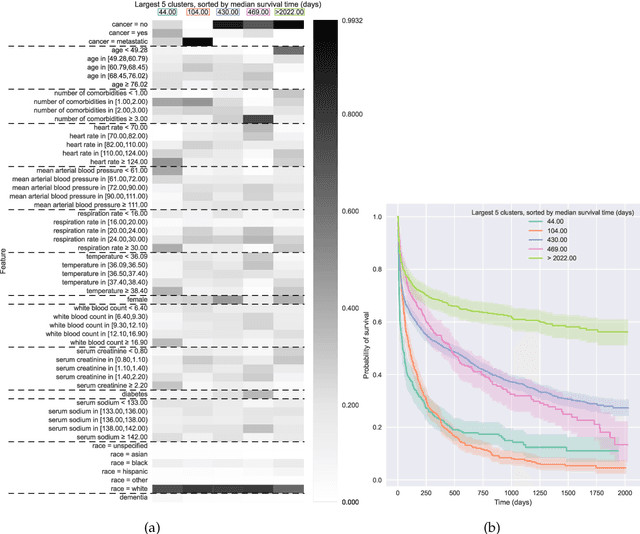
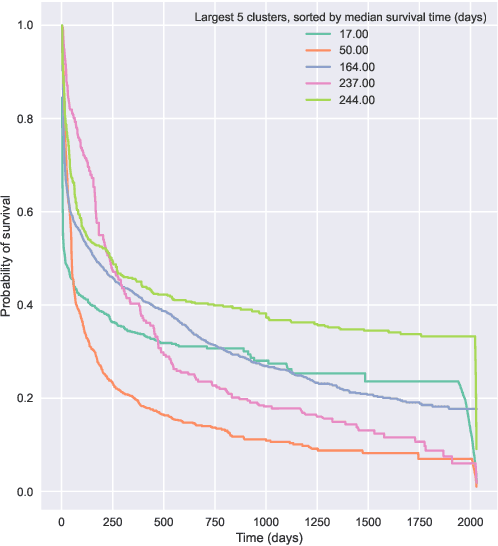
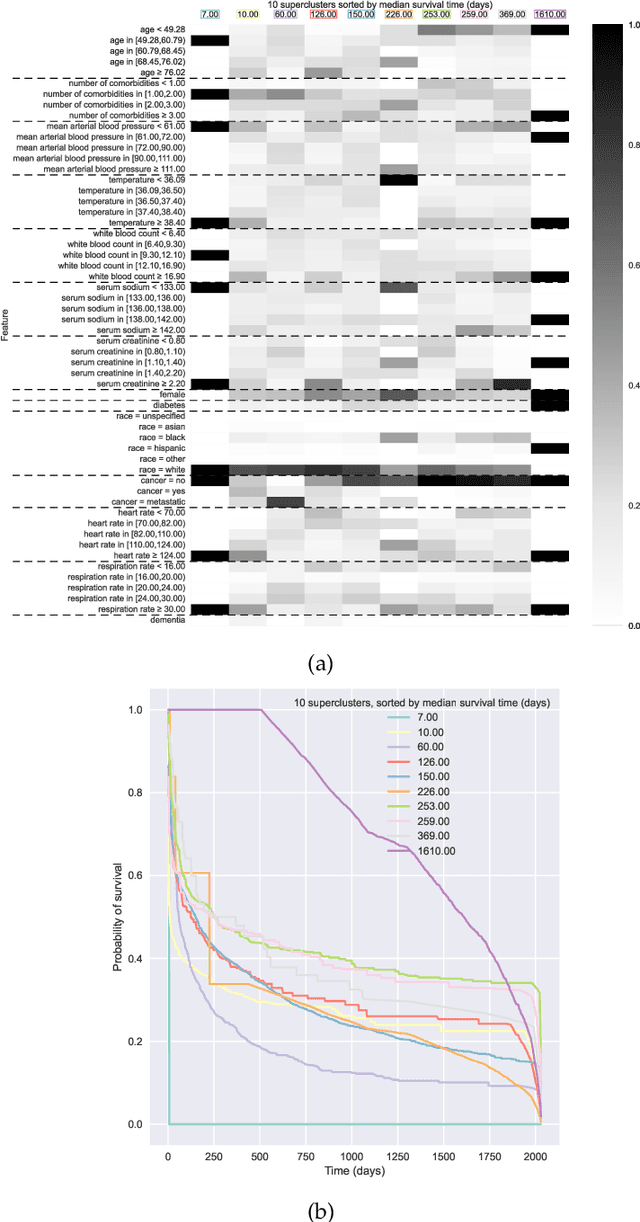
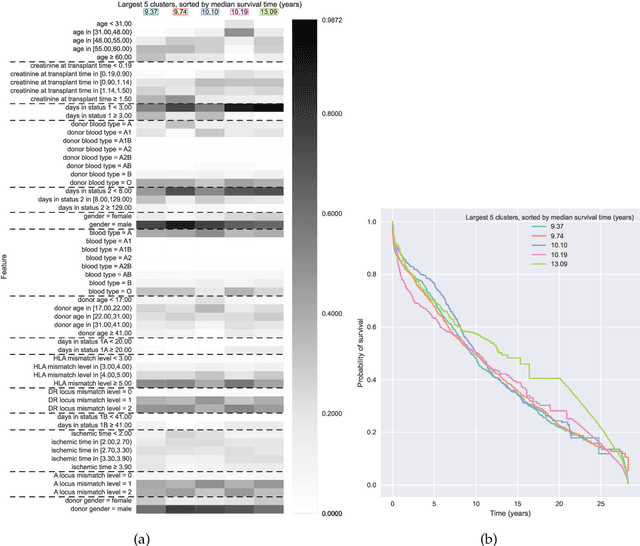
Kernel survival analysis models estimate individual survival distributions with the help of a kernel function, which measures the similarity between any two data points. Such a kernel function can be learned using deep kernel survival models. In this paper, we present a new deep kernel survival model called a survival kernet, which scales to large datasets in a manner that is amenable to model interpretation and also theoretical analysis. Specifically, the training data are partitioned into clusters based on a recently developed training set compression scheme for classification and regression called kernel netting that we extend to the survival analysis setting. At test-time, each data point is represented as a weighted combination of these clusters, and each such cluster can be visualized. For a special case of survival kernets, we establish a finite-sample error bound on predicted survival distributions that is, up to a log factor, optimal. Whereas scalability at test time is achieved using the aforementioned kernel netting compression strategy, scalability during training is achieved by a warm-start procedure based on tree ensembles such as XGBoost and a heuristic approach to accelerating neural architecture search. On three standard survival analysis datasets of varying sizes (up to roughly 3 million data points), we show that survival kernets are highly competitive with the best of baselines tested in terms of concordance index. Our code is available at: https://github.com/georgehc/survival-kernets