 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey: Transformer based Video-Language Pre-training
Paper and Code
Sep 21, 2021

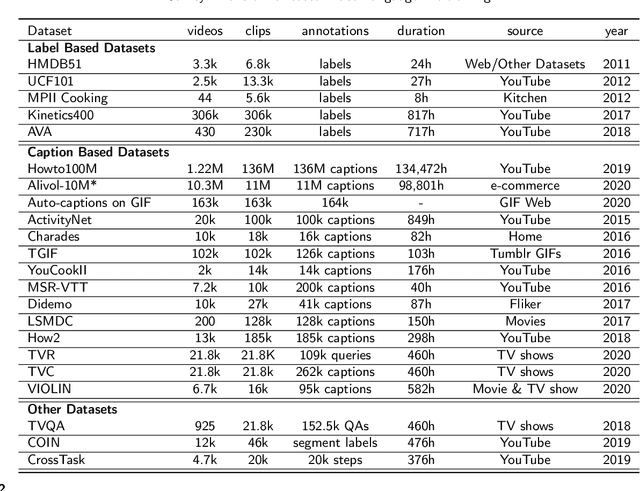

Inspired by the success of transformer-based pre-training methods on natural language tasks and further computer vision tasks, researchers have begun to apply transformer to video processing. This survey aims to give a comprehensive overview on transformer-based pre-training methods for Video-Language learning. We first briefly introduce the transformer tructure as the background knowledge, including attention mechanism, position encoding etc. We then describe the typical paradigm of pre-training & fine-tuning on Video-Language processing in terms of proxy tasks, downstream tasks and commonly used video datasets. Next, we categorize transformer models into Single-Stream and Multi-Stream structures, highlight their innovations and compare their performances. Finally, we analyze and discuss the current challenges and possible future research directions for Video-Language pre-training.