 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey & Experiment: Towards the Learning Accuracy
Paper and Code
Dec 18, 2010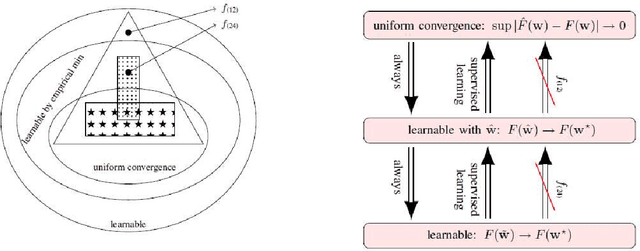
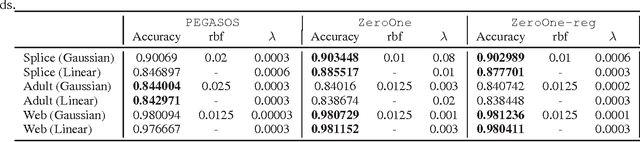
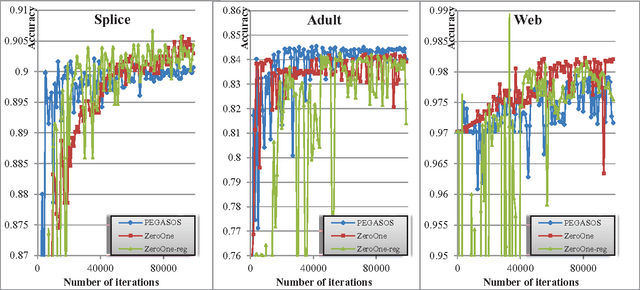
To attain the best learning accuracy, people move on with difficulties and frustrations. Though one can optimize the empirical objective using a given set of samples, its generalization ability to the entire sample distribution remains questionable. Even if a fair generalization guarantee is offered, one still wants to know what is to happen if the regularizer is removed, and/or how well the artificial loss (like the hinge loss) relates to the accuracy. For such reason, this report surveys four different trials towards the learning accuracy, embracing the major advances in supervised learning theory in the past four years. Starting from the generic setting of learning, the first two trials introduce the best optimization and generalization bounds for convex learning, and the third trial gets rid of the regularizer. As an innovative attempt, the fourth trial studies the optimization when the objective is exactly the accuracy, in the special case of binary classification. This report also analyzes the last trial through experiments.