 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical-VQA: Visual Question Answering in Surgical Scenes using Transformer
Paper and Code


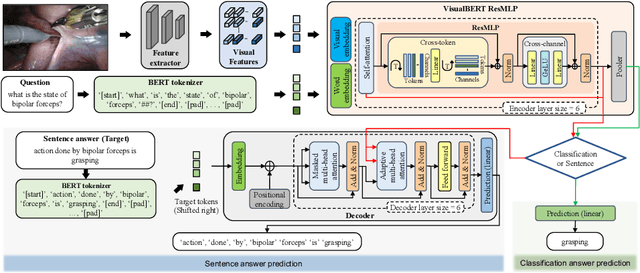

Visual question answering (VQA) in surgery is largely unexplored. Expert surgeons are scarce and are often overloaded with clinical and academic workloads. This overload often limits their time answering questionnaires from patients, medical students or junior residents related to surgical procedures. At times, students and junior residents also refrain from asking too many questions during classes to reduce disruption. While computer-aided simulators and recording of past surgical procedures have been made available for them to observe and improve their skills, they still hugely rely on medical experts to answer their questions. Having a Surgical-VQA system as a reliable 'second opinion' could act as a backup and ease the load on the medical experts in answering these questions. The lack of annotated medical data and the presence of domain-specific terms has limited the exploration of VQA for surgical procedures. In this work, we design a Surgical-VQA task that answers questionnaires on surgical procedures based on the surgical scene. Extending the MICCAI endoscopic vision challenge 2018 dataset and workflow recognition dataset further, we introduce two Surgical-VQA datasets with classification and sentence-based answers. To perform Surgical-VQA, we employ vision-text transformers models. We further introduce a residual MLP-based VisualBert encoder model that enforces interaction between visual and text tokens, improving performance in classification-based answering. Furthermore, we study the influence of the number of input image patches and temporal visual features on the model performance in both classification and sentence-based answering.