 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Paper and Code
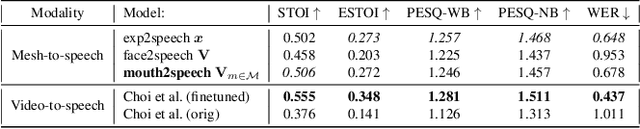
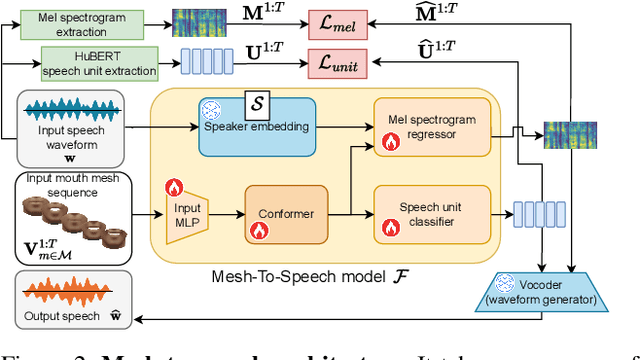

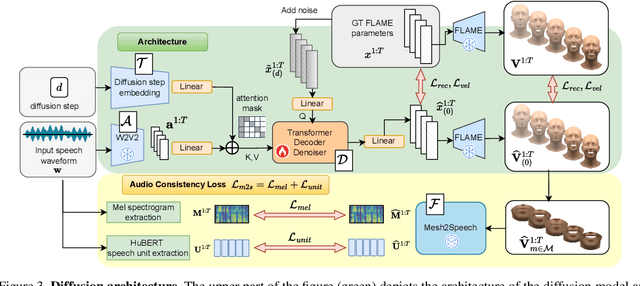
In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations.