 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Prompting: Utilizing Model-Independent Contextual Data to Reduce Data Annotation Required in Visual Commonsense Tasks
Paper and Code
Apr 25, 2022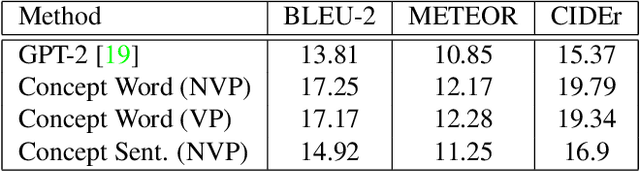

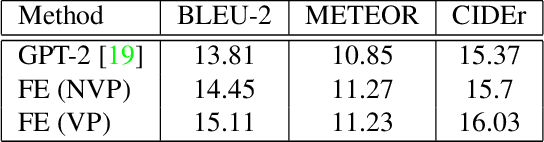
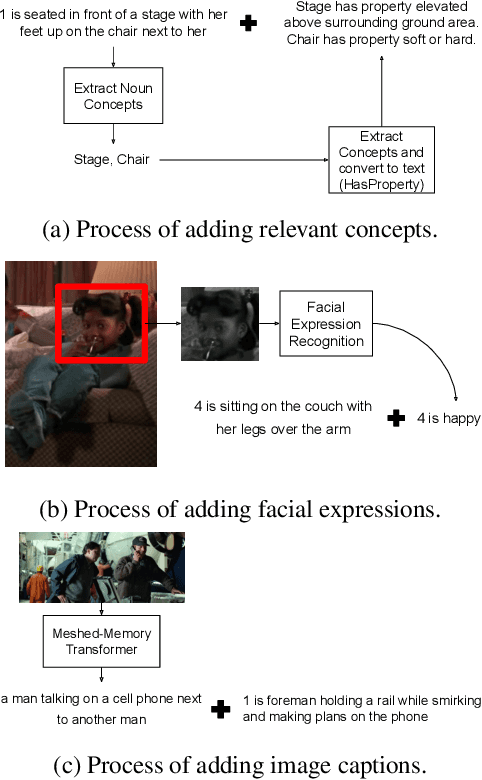
Pre-trained language models have shown excellent results in few-shot learning scenarios using in-context learning. Although it is impressive, the size of language models can be prohibitive to make them usable in on-device applications, such as sensors or smartphones. With smaller language models, task-specific data annotation is needed to fine-tune the language model for a specific purpose. However, data annotation can have a substantial financial and time burden for small research groups, startups, and even companies. In this paper, we analyze different prompt-based fine-tuning techniques to improve results on both language and multimodal causal transformer models. To evaluate our results, we use a dataset focusing on visual commonsense reasoning in time. Our results show that by simple model-agnostic prompt-based fine-tuning, comparable results can be reached by only using 35%-40% of the fine-tuning training dataset. The proposed approaches result in significant time and financial savings. As the proposed methods make minimal architectural assumptions, other researchers can use the results in their transformer models with minimal adaptations. We plan to release the source code freely to make it easier for the community to use and contribute to our work.