 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubword Sampling for Low Resource Word Alignment
Paper and Code
Dec 21, 2020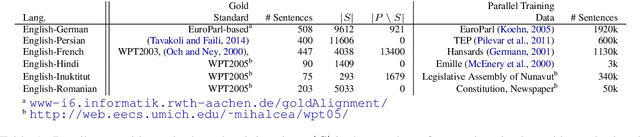

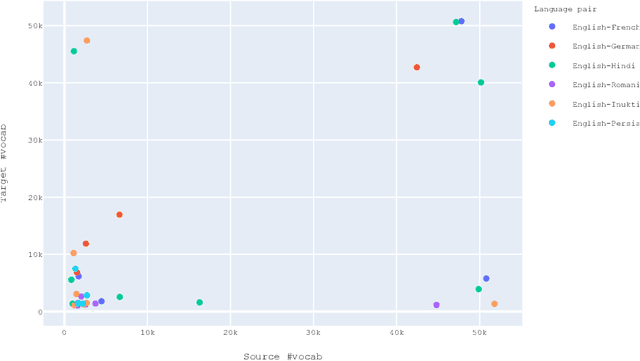
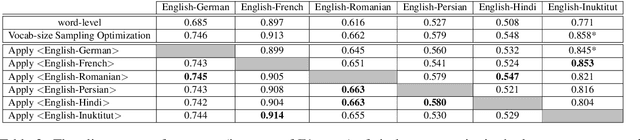
Annotation projection is an important area in NLP that can greatly contribute to creating language resources for low-resource languages. Word alignment plays a key role in this setting. However, most of the existing word alignment methods are designed for a high resource setting in machine translation where millions of parallel sentences are available. This amount reduces to a few thousands of sentences when dealing with low-resource languages failing the existing established IBM models. In this paper, we propose subword sampling-based alignment of text units. This method's hypothesis is that the aggregation of different granularities of text for certain language pairs can help word-level alignment. For certain languages for which gold-standard alignments exist, we propose an iterative Bayesian optimization framework to optimize selecting possible subwords from the space of possible subword representations of the source and target sentences. We show that the subword sampling method consistently outperforms word-level alignment on six language pairs: English-German, English-French, English-Romanian, English-Persian, English-Hindi, and English-Inuktitut. In addition, we show that the hyperparameters learned for certain language pairs can be applied to other languages at no supervision and consistently improve the alignment results. We observe that using $5K$ parallel sentences together with our proposed subword sampling approach, we obtain similar F1 scores to the use of $100K$'s of parallel sentences in existing word-level fast-align/eflomal alignment methods.