 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubsampling Bias and The Best-Discrepancy Systematic Cross Validation
Paper and Code
Jul 04, 2019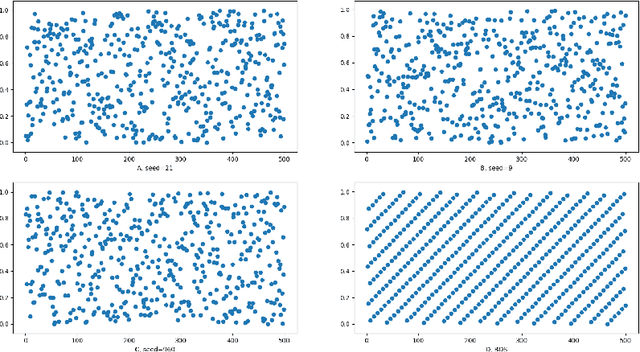
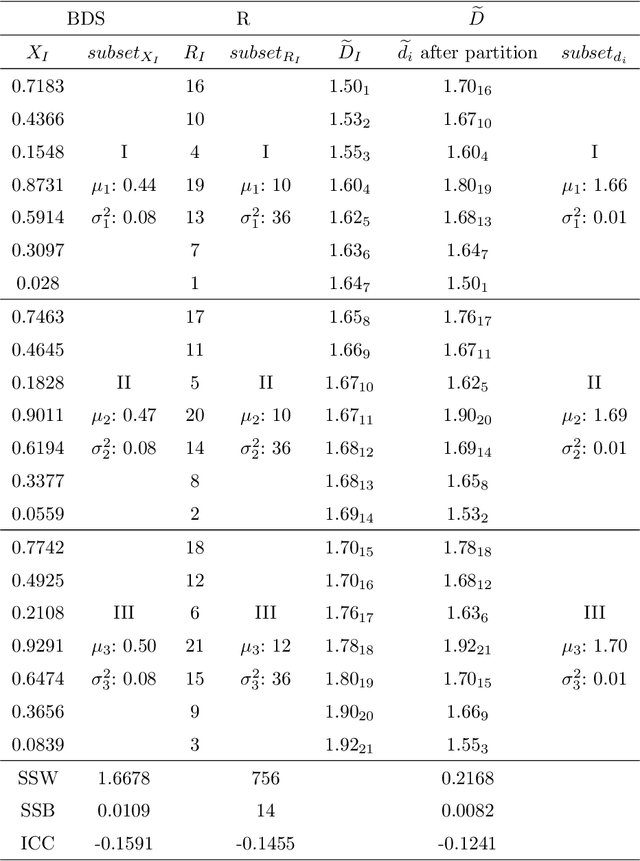
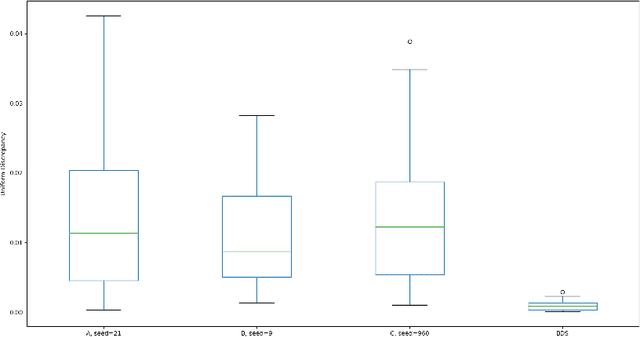

Statistical machine learning models should be evaluated and validated before putting to work. Conventional k-fold Monte Carlo Cross-Validation (MCCV) procedure uses a pseudo-random sequence to partition instances into k subsets, which usually causes subsampling bias, inflates generalization errors and jeopardizes the reliability and effectiveness of cross-validation. Based on ordered systematic sampling theory in statistics and low-discrepancy sequence theory in number theory, we propose a new k-fold cross-validation procedure by replacing a pseudo-random sequence with a best-discrepancy sequence, which ensures low subsampling bias and leads to more precise Expected-Prediction-Error estimates. Experiments with 156 benchmark datasets and three classifiers (logistic regression, decision tree and naive bayes) show that in general, our cross-validation procedure can extrude subsampling bias in the MCCV by lowering the EPE around 7.18% and the variances around 26.73%. In comparison, the stratified MCCV can reduce the EPE and variances of the MCCV around 1.58% and 11.85% respectively. The Leave-One-Out (LOO) can lower the EPE around 2.50% but its variances are much higher than the any other CV procedure. The computational time of our cross-validation procedure is just 8.64% of the MCCV, 8.67% of the stratified MCCV and 16.72% of the LOO. Experiments also show that our approach is more beneficial for datasets characterized by relatively small size and large aspect ratio. This makes our approach particularly pertinent when solving bioscience classification problems. Our proposed systematic subsampling technique could be generalized to other machine learning algorithms that involve random subsampling mechanism.