 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Text Generation Using Wasserstein Autoencoders with a Mixture of Gaussian Prior
Paper and Code
Nov 10, 2019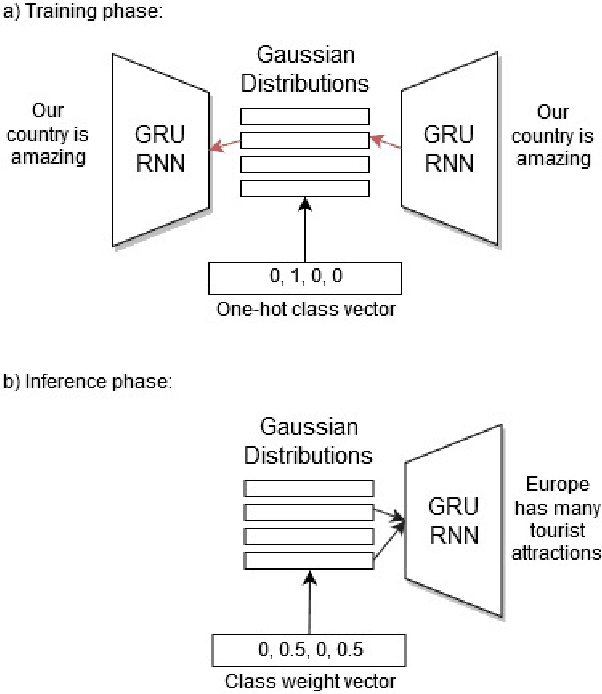
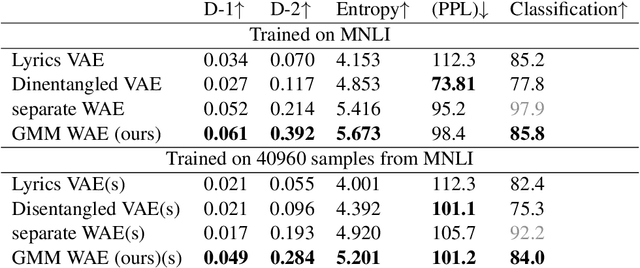

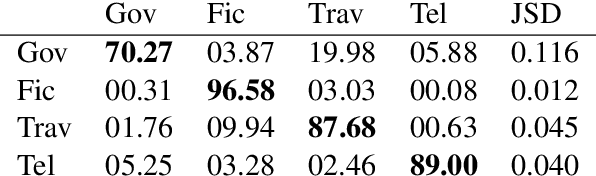
Wasserstein autoencoders are effective for text generation. They do not however provide any control over the style and topic of the generated sentences if the dataset has multiple classes and includes different topics. In this work, we present a semi-supervised approach for generating stylized sentences. Our model is trained on a multi-class dataset and learns the latent representation of the sentences using a mixture of Gaussian prior without any adversarial losses. This allows us to generate sentences in the style of a specified class or multiple classes by sampling from their corresponding prior distributions. Moreover, we can train our model on relatively small datasets and learn the latent representation of a specified class by adding external data with other styles/classes to our dataset. While a simple WAE or VAE cannot generate diverse sentences in this case, generated sentences with our approach are diverse, fluent, and preserve the style and the content of the desired classes.