 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylistic Fingerprints, POS-tags and Inflected Languages: A Case Study in Polish
Paper and Code
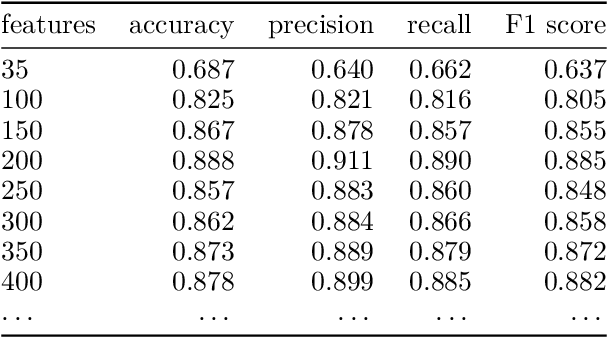
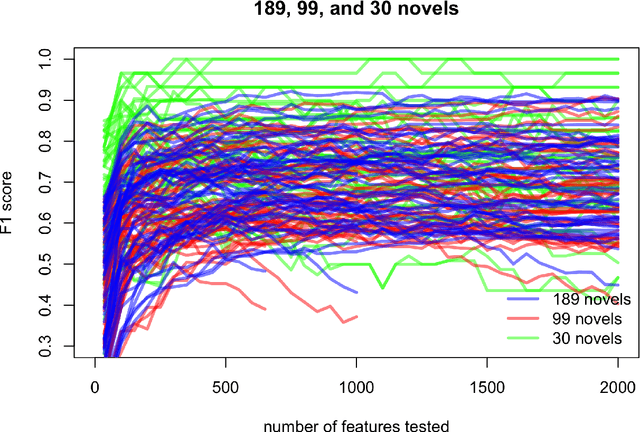
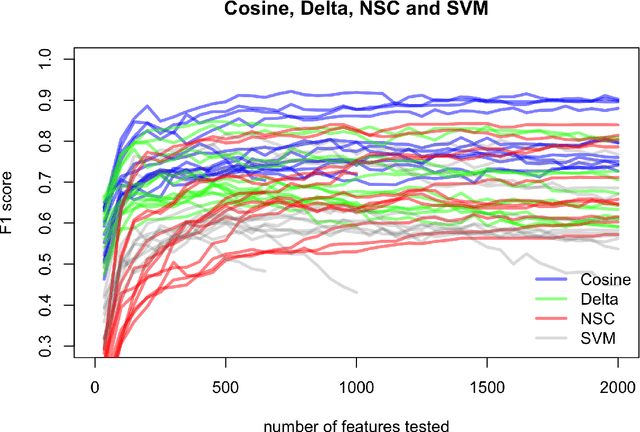
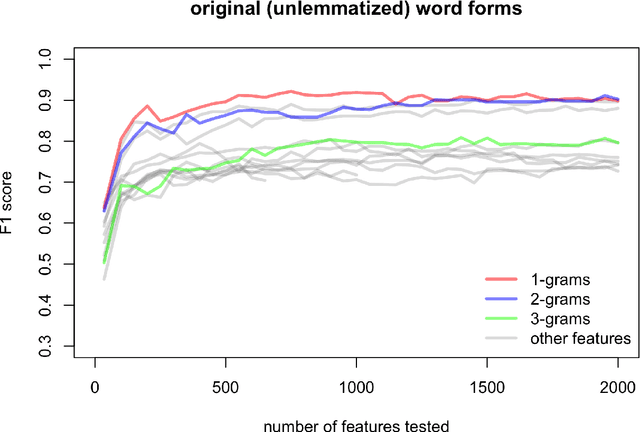
In stylometric investigations, frequencies of the most frequent words (MFWs) and character n-grams outperform other style-markers, even if their performance varies significantly across languages. In inflected languages, word endings play a prominent role, and hence different word forms cannot be recognized using generic text tokenization. Countless inflected word forms make frequencies sparse, making most statistical procedures complicated. Presumably, applying one of the NLP techniques, such as lemmatization and/or parsing, might increase the performance of classification. The aim of this paper is to examine the usefulness of grammatical features (as assessed via POS-tag n-grams) and lemmatized forms in recognizing authorial profiles, in order to address the underlying issue of the degree of freedom of choice within lexis and grammar. Using a corpus of Polish novels, we performed a series of supervised authorship attribution benchmarks, in order to compare the classification accuracy for different types of lexical and syntactic style-markers. Even if the performance of POS-tags as well as lemmatized forms was notoriously worse than that of lexical markers, the difference was not substantial and never exceeded ca. 15%.