Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Transfer to Calvin and Hobbes comics using Stable Diffusion
Paper and Code
Dec 07, 2023
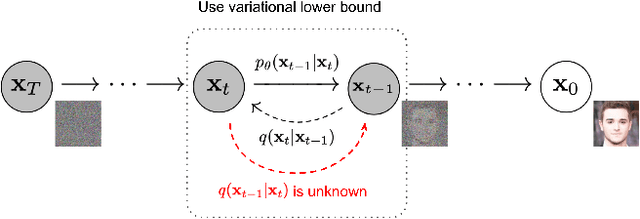


This project report summarizes our journey to perform stable diffusion fine-tuning on a dataset containing Calvin and Hobbes comics. The purpose is to convert any given input image into the comic style of Calvin and Hobbes, essentially performing style transfer. We train stable-diffusion-v1.5 using Low Rank Adaptation (LoRA) to efficiently speed up the fine-tuning process. The diffusion itself is handled by a Variational Autoencoder (VAE), which is a U-net. Our results were visually appealing for the amount of training time and the quality of input data that went into training.
* Project report for ECE 371Q Digital Image Processing at UT Austin
View paper on