 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy on the Fairness of Speaker Verification Systems on Underrepresented Accents in English
Paper and Code
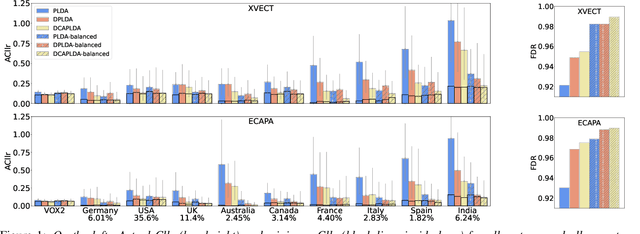

Speaker verification (SV) systems are currently being used to make sensitive decisions like giving access to bank accounts or deciding whether the voice of a suspect coincides with that of the perpetrator of a crime. Ensuring that these systems are fair and do not disfavor any particular group is crucial. In this work, we analyze the performance of several state-of-the-art SV systems across groups defined by the accent of the speakers when speaking English. To this end, we curated a new dataset based on the VoxCeleb corpus where we carefully selected samples from speakers with accents from different countries. We use this dataset to evaluate system performance for several SV systems trained with VoxCeleb data. We show that, while discrimination performance is reasonably robust across accent groups, calibration performance degrades dramatically on some accents that are not well represented in the training data. Finally, we show that a simple data balancing approach mitigates this undesirable bias, being particularly effective when applied to our recently-proposed discriminative condition-aware backend.