 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Self-Attention Weights Encode Semantics in Sentiment Analysis
Paper and Code
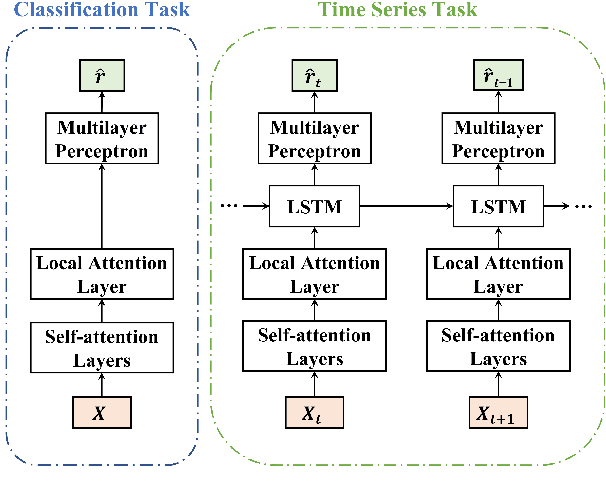
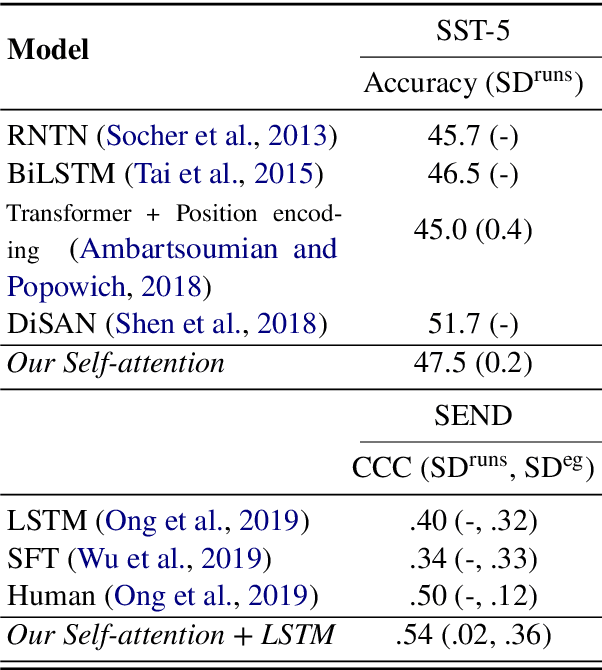
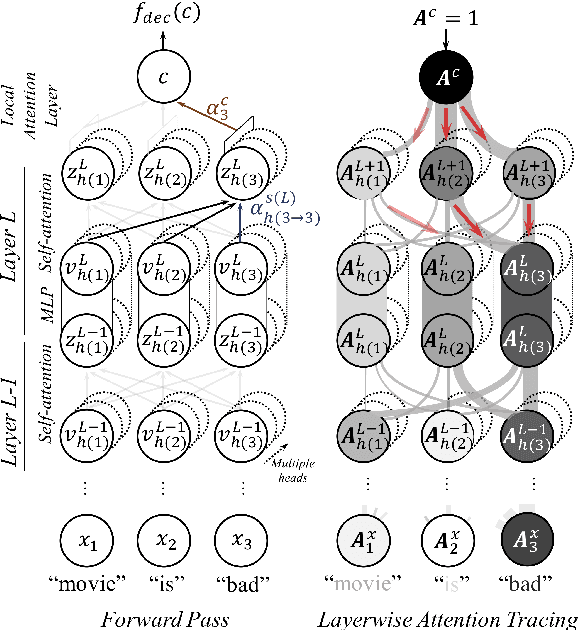
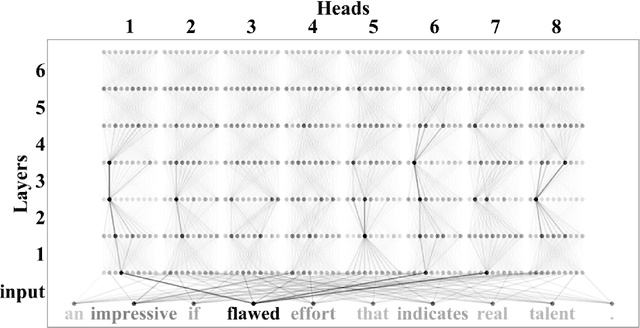
Neural attention, especially the self-attention made popular by the Transformer, has become the workhorse of state-of-the-art natural language processing (NLP) models. Very recent work suggests that the self-attention in the Transformer encodes syntactic information; Here, we show that self-attention scores encode semantics by considering sentiment analysis tasks. In contrast to gradient-based feature attribution methods, we propose a simple and effective Layer-wise Attention Tracing (LAT) method to analyze structured attention weights. We apply our method to Transformer models trained on two tasks that have surface dissimilarities, but share common semantics---sentiment analysis of movie reviews and time-series valence prediction in life story narratives. Across both tasks, words with high aggregated attention weights were rich in emotional semantics, as quantitatively validated by an emotion lexicon labeled by human annotators. Our results show that structured attention weights encode rich semantics in sentiment analysis, and match human interpretations of semantics.