 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural risk minimization for quantum linear classifiers
Paper and Code
May 12, 2021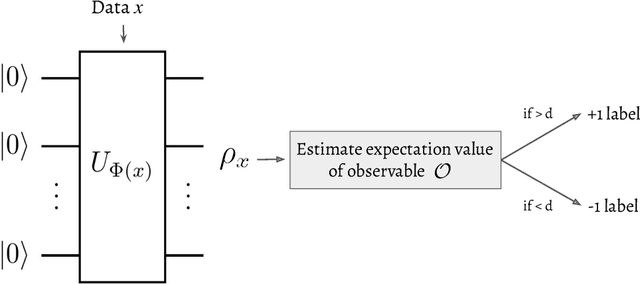
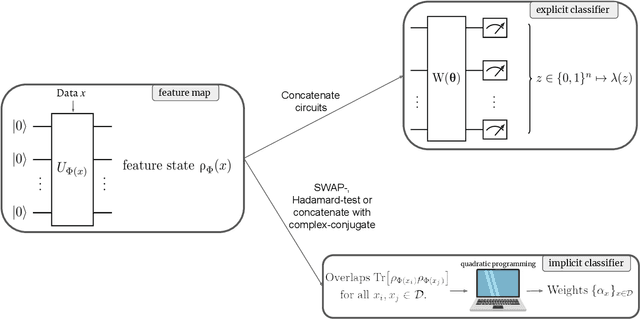
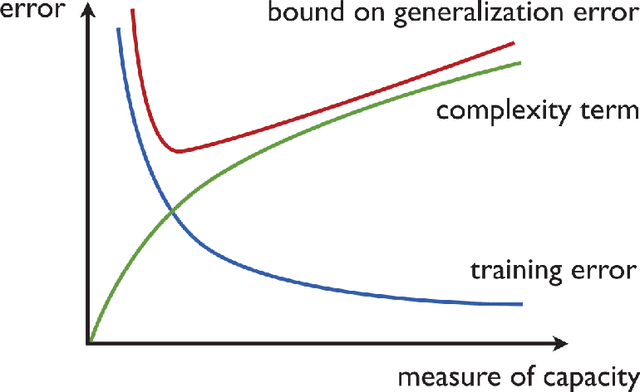
Quantum machine learning (QML) stands out as one of the typically highlighted candidates for quantum computing's near-term "killer application". In this context, QML models based on parameterized quantum circuits comprise a family of machine learning models that are well suited for implementations on near-term devices and that can potentially harness computational powers beyond what is efficiently achievable on a classical computer. However, how to best use these models -- e.g., how to control their expressivity to best balance between training accuracy and generalization performance -- is far from understood. In this paper we investigate capacity measures of two closely related QML models called explicit and implicit quantum linear classifiers (also called the quantum variational method and quantum kernel estimator) with the objective of identifying new ways to implement structural risk minimization -- i.e., how to balance between training accuracy and generalization performance. In particular, we identify that the rank and Frobenius norm of the observables used in the QML model closely control the model's capacity. Additionally, we theoretically investigate the effect that these model parameters have on the training accuracy of the QML model. Specifically, we show that there exists datasets that require a high-rank observable for correct classification, and that there exists datasets that can only be classified with a given margin using an observable of at least a certain Frobenius norm. Our results provide new options for performing structural risk minimization for QML models.