 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Compression of Convolutional Neural Networks Based on Greedy Filter Pruning
Paper and Code
Jul 21, 2017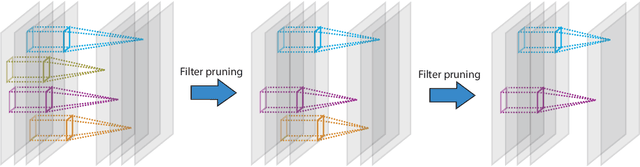
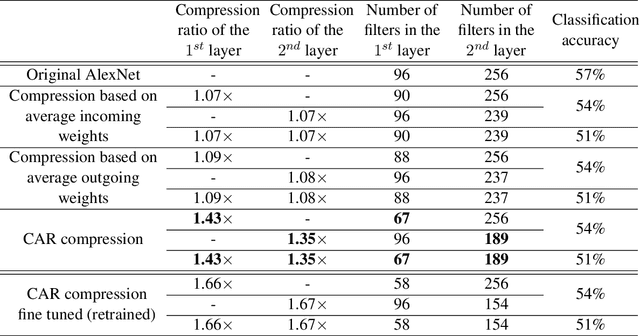


Convolutional neural networks (CNNs) have state-of-the-art performance on many problems in machine vision. However, networks with superior performance often have millions of weights so that it is difficult or impossible to use CNNs on computationally limited devices or to humanly interpret them. A myriad of CNN compression approaches have been proposed and they involve pruning and compressing the weights and filters. In this article, we introduce a greedy structural compression scheme that prunes filters in a trained CNN. We define a filter importance index equal to the classification accuracy reduction (CAR) of the network after pruning that filter (similarly defined as RAR for regression). We then iteratively prune filters based on the CAR index. This algorithm achieves substantially higher classification accuracy in AlexNet compared to other structural compression schemes that prune filters. Pruning half of the filters in the first or second layer of AlexNet, our CAR algorithm achieves 26% and 20% higher classification accuracies respectively, compared to the best benchmark filter pruning scheme. Our CAR algorithm, combined with further weight pruning and compressing, reduces the size of first or second convolutional layer in AlexNet by a factor of 42, while achieving close to original classification accuracy through retraining (or fine-tuning) network. Finally, we demonstrate the interpretability of CAR-compressed CNNs by showing that our algorithm prunes filters with visually redundant functionalities. In fact, out of top 20 CAR-pruned filters in AlexNet, 17 of them in the first layer and 14 of them in the second layer are color-selective filters as opposed to shape-selective filters. To our knowledge, this is the first reported result on the connection between compression and interpretability of CNNs.