 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Decision-Making in the Presence of Information Asymmetry: Provably Efficient RL with Algorithmic Instruments
Paper and Code
Aug 23, 2022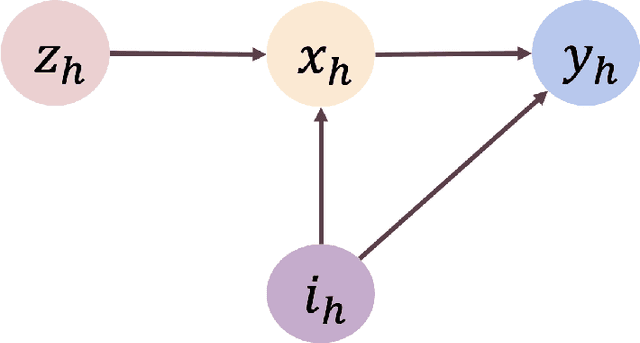
We study offline reinforcement learning under a novel model called strategic MDP, which characterizes the strategic interactions between a principal and a sequence of myopic agents with private types. Due to the bilevel structure and private types, strategic MDP involves information asymmetry between the principal and the agents. We focus on the offline RL problem, where the goal is to learn the optimal policy of the principal concerning a target population of agents based on a pre-collected dataset that consists of historical interactions. The unobserved private types confound such a dataset as they affect both the rewards and observations received by the principal. We propose a novel algorithm, Pessimistic policy Learning with Algorithmic iNstruments (PLAN), which leverages the ideas of instrumental variable regression and the pessimism principle to learn a near-optimal principal's policy in the context of general function approximation. Our algorithm is based on the critical observation that the principal's actions serve as valid instrumental variables. In particular, under a partial coverage assumption on the offline dataset, we prove that PLAN outputs a $1 / \sqrt{K}$-optimal policy with $K$ being the number of collected trajectories. We further apply our framework to some special cases of strategic MDP, including strategic regression, strategic bandit, and noncompliance in recommendation systems.