 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Online Optimization for Cyber-Physical and Robotic Systems
Paper and Code
Apr 08, 2024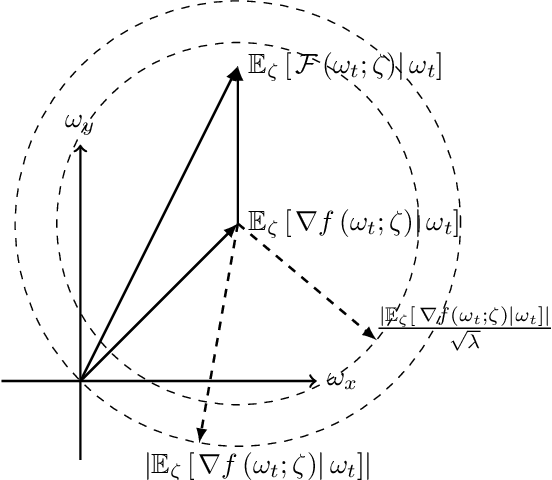


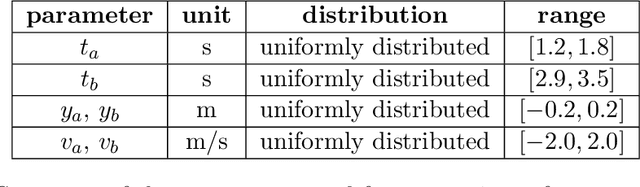
We propose a novel gradient-based online optimization framework for solving stochastic programming problems that frequently arise in the context of cyber-physical and robotic systems. Our problem formulation accommodates constraints that model the evolution of a cyber-physical system, which has, in general, a continuous state and action space, is nonlinear, and where the state is only partially observed. We also incorporate an approximate model of the dynamics as prior knowledge into the learning process and show that even rough estimates of the dynamics can significantly improve the convergence of our algorithms. Our online optimization framework encompasses both gradient descent and quasi-Newton methods, and we provide a unified convergence analysis of our algorithms in a non-convex setting. We also characterize the impact of modeling errors in the system dynamics on the convergence rate of the algorithms. Finally, we evaluate our algorithms in simulations of a flexible beam, a four-legged walking robot, and in real-world experiments with a ping-pong playing robot.