 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTL-SGD: Speeding Up Local SGD with Stagewise Communication Period
Paper and Code
Jun 11, 2020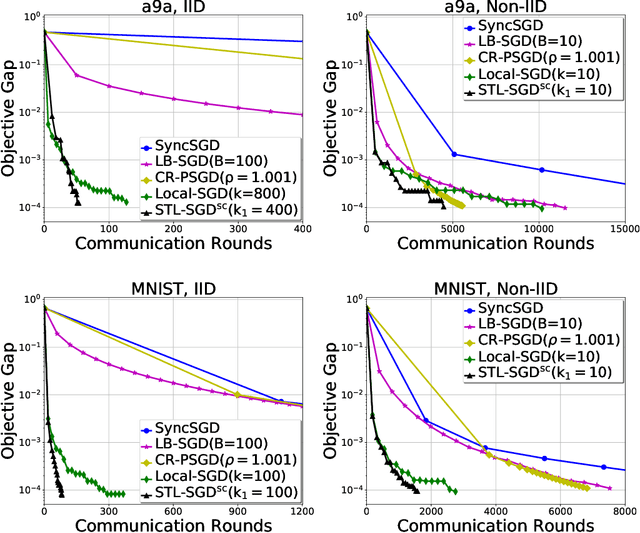

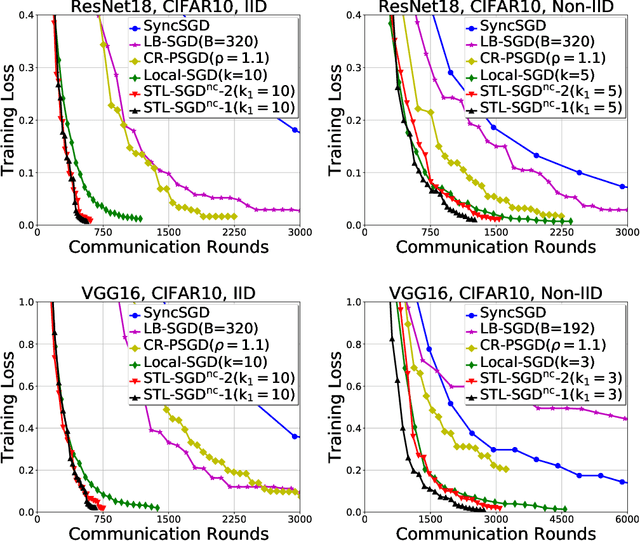

Distributed parallel stochastic gradient descent algorithms are workhorses for large scale machine learning tasks. Among them, local stochastic gradient descent (Local SGD) has attracted significant attention due to its low communication complexity. Previous studies prove that the communication complexity of Local SGD with a fixed or an adaptive communication period is in the order of $O (N^{\frac{3}{2}} T^{\frac{1}{2}})$ and $O (N^{\frac{3}{4}} T^{\frac{3}{4}})$ when the data distributions on clients are identical (IID) or otherwise (Non-IID). In this paper, to accelerate the convergence by reducing the communication complexity, we propose \textit{ST}agewise \textit{L}ocal \textit{SGD} (STL-SGD), which increases the communication period gradually along with decreasing learning rate. We prove that STL-SGD can keep the same convergence rate and linear speedup as mini-batch SGD. In addition, as the benefit of increasing the communication period, when the objective is strongly convex or satisfies the Polyak-\L ojasiewicz condition, the communication complexity of STL-SGD is $O (N \log{T})$ and $O (N^{\frac{1}{2}} T^{\frac{1}{2}})$ for the IID case and the Non-IID case respectively, achieving significant improvements over Local SGD. Experiments on both convex and non-convex problems demonstrate the superior performance of STL-SGD.