 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTHG: Spatial-Temporal Heterogeneous Graph Learning for Advanced Audio-Visual Diarization
Paper and Code
Jun 18, 2023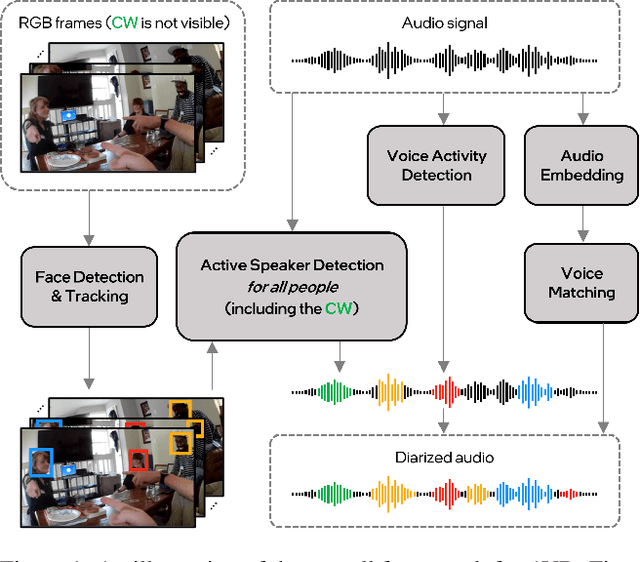
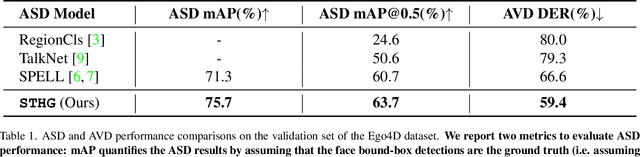
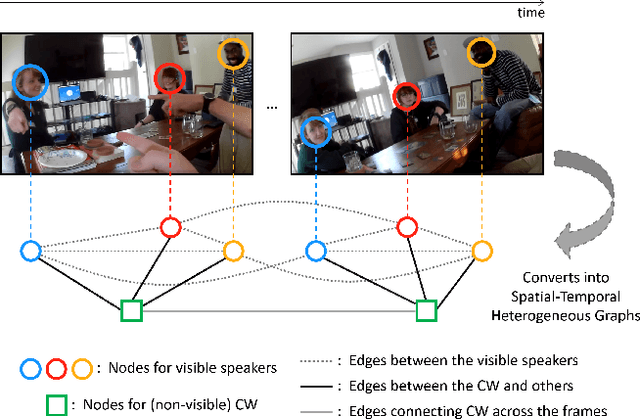
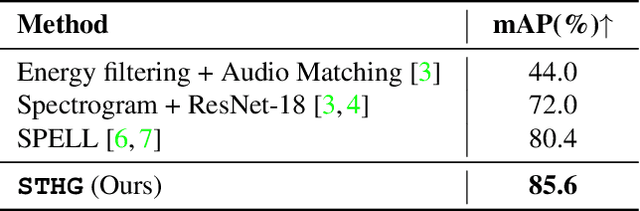
This report introduces our novel method named STHG for the Audio-Visual Diarization task of the Ego4D Challenge 2023. Our key innovation is that we model all the speakers in a video using a single, unified heterogeneous graph learning framework. Unlike previous approaches that require a separate component solely for the camera wearer, STHG can jointly detect the speech activities of all people including the camera wearer. Our final method obtains 61.1% DER on the test set of Ego4D, which significantly outperforms all the baselines as well as last year's winner. Our submission achieved 1st place in the Ego4D Challenge 2023. We additionally demonstrate that applying the off-the-shelf speech recognition system to the diarized speech segments by STHG produces a competitive performance on the Speech Transcription task of this challenge.