 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepNet: Spatial-temporal Part-aware Network for Sign Language Recognition
Paper and Code
Dec 25, 2022
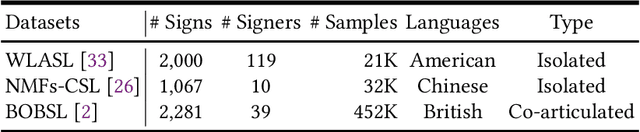

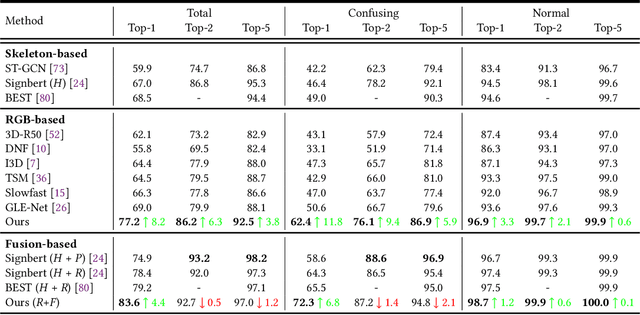
Sign language recognition (SLR) aims to overcome the communication barrier for the people with deafness or the people with hard hearing. Most existing approaches can be typically divided into two lines, i.e., Skeleton-based and RGB-based methods, but both the two lines of methods have their limitations. RGB-based approaches usually overlook the fine-grained hand structure, while Skeleton-based methods do not take the facial expression into account. In attempts to address both limitations, we propose a new framework named Spatial-temporal Part-aware network (StepNet), based on RGB parts. As the name implies, StepNet consists of two modules: Part-level Spatial Modeling and Part-level Temporal Modeling. Particularly, without using any keypoint-level annotations, Part-level Spatial Modeling implicitly captures the appearance-based properties, such as hands and faces, in the feature space. On the other hand, Part-level Temporal Modeling captures the pertinent properties over time by implicitly mining the long-short term context. Extensive experiments show that our StepNet, thanks to Spatial-temporal modules, achieves competitive Top-1 Per-instance accuracy on three widely-used SLR benchmarks, i.e., 56.89% on WLASL, 77.2% on NMFs-CSL, and 77.1% on BOBSL. Moreover, the proposed method is compatible with the optical flow input, and can yield higher performance if fused. We hope that this work can serve as a preliminary step for the people with deafness.