 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Deep Feature Learning with Backward Aligned Feature Updates
Paper and Code
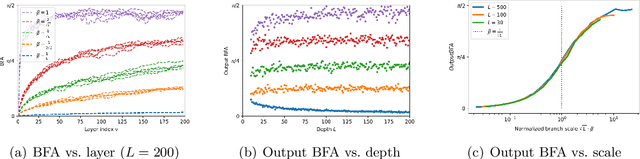
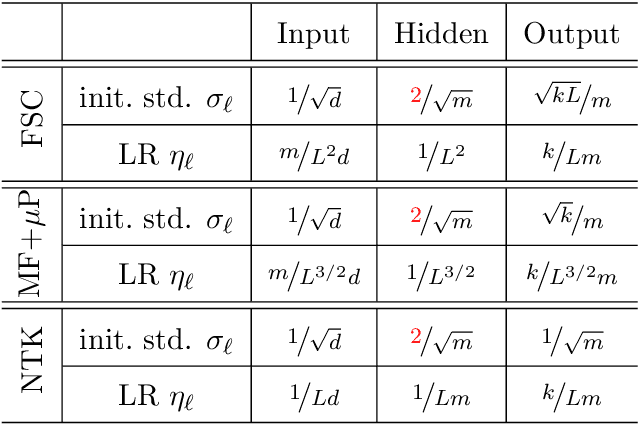
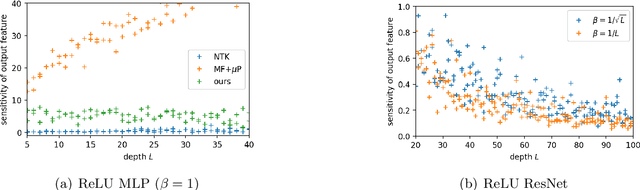

Deep learning succeeds by doing hierarchical feature learning, yet tuning Hyper-Parameters (HP) such as initialization scales, learning rates etc., only give indirect control over this behavior. In this paper, we propose the alignment between the feature updates and the backward pass as a key notion to predict, measure and control feature learning. On the one hand, we show that when alignment holds, the magnitude of feature updates after one SGD step is related to the magnitude of the forward and backward passes by a simple and general formula. This leads to techniques to automatically adjust HPs (initialization scales and learning rates) at initialization and throughout training to attain a desired feature learning behavior. On the other hand, we show that, at random initialization, this alignment is determined by the spectrum of a certain kernel, and that well-conditioned layer-to-layer Jacobians (aka dynamical isometry) implies alignment. Finally, we investigate ReLU MLPs and ResNets in the large width-then-depth limit. Combining hints from random matrix theory and numerical experiments, we show that (i) in MLP with iid initializations, alignment degenerates with depth, making it impossible to start training, and that (ii) in ResNets, the branch scale $1/\sqrt{\text{depth}}$ is the only one maintaining non-trivial alignment at infinite depth.