 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically efficient thinning of a Markov chain sampler
Paper and Code
Apr 11, 2017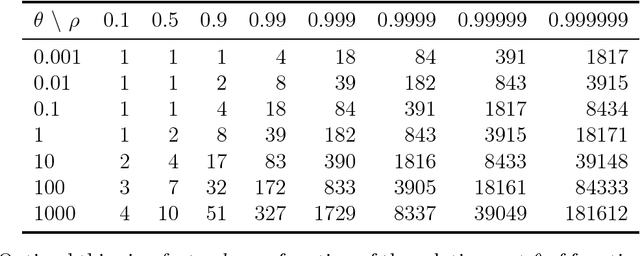
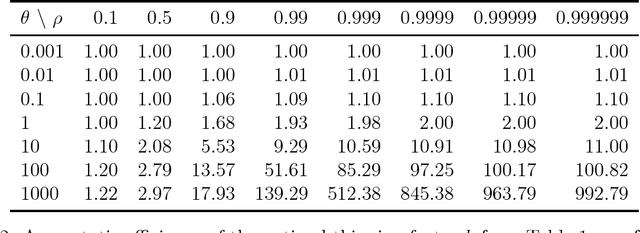
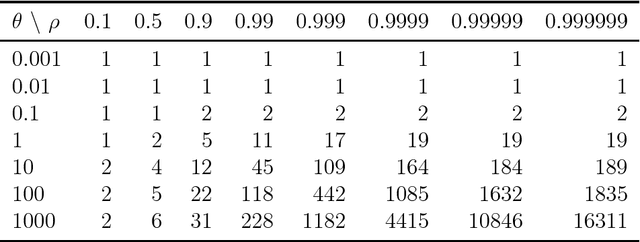
It is common to subsample Markov chain output to reduce the storage burden. Geyer (1992) shows that discarding $k-1$ out of every $k$ observations will not improve statistical efficiency, as quantified through variance in a given computational budget. That observation is often taken to mean that thinning MCMC output cannot improve statistical efficiency. Here we suppose that it costs one unit of time to advance a Markov chain and then $\theta>0$ units of time to compute a sampled quantity of interest. For a thinned process, that cost $\theta$ is incurred less often, so it can be advanced through more stages. Here we provide examples to show that thinning will improve statistical efficiency if $\theta$ is large and the sample autocorrelations decay slowly enough. If the lag $\ell\ge1$ autocorrelations of a scalar measurement satisfy $\rho_\ell\ge\rho_{\ell+1}\ge0$, then there is always a $\theta<\infty$ at which thinning becomes more efficient for averages of that scalar. Many sample autocorrelation functions resemble first order AR(1) processes with $\rho_\ell =\rho^{|\ell|}$ for some $-1<\rho<1$. For an AR(1) process it is possible to compute the most efficient subsampling frequency $k$. The optimal $k$ grows rapidly as $\rho$ increases towards $1$. The resulting efficiency gain depends primarily on $\theta$, not $\rho$. Taking $k=1$ (no thinning) is optimal when $\rho\le0$. For $\rho>0$ it is optimal if and only if $\theta \le (1-\rho)^2/(2\rho)$. This efficiency gain never exceeds $1+\theta$. This paper also gives efficiency bounds for autocorrelations bounded between those of two AR(1) processes.