 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Properties of Deep Neural Networks with Dependent Data
Paper and Code
Oct 14, 2024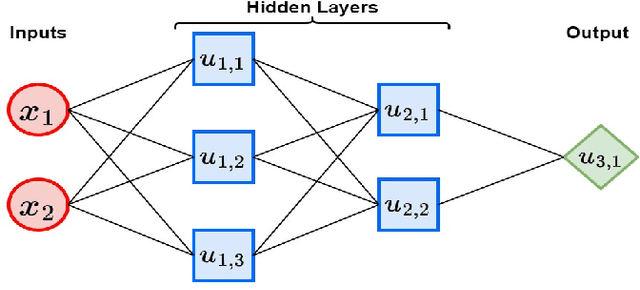

This paper establishes statistical properties of deep neural network (DNN) estimators under dependent data. Two general results for nonparametric sieve estimators directly applicable to DNNs estimators are given. The first establishes rates for convergence in probability under nonstationary data. The second provides non-asymptotic probability bounds on $\mathcal{L}^{2}$-errors under stationary $\beta$-mixing data. I apply these results to DNN estimators in both regression and classification contexts imposing only a standard H\"older smoothness assumption. These results are then used to demonstrate how asymptotic inference can be conducted on the finite dimensional parameter of a partially linear regression model after first-stage DNN estimation of infinite dimensional parameters. The DNN architectures considered are common in applications, featuring fully connected feedforward networks with any continuous piecewise linear activation function, unbounded weights, and a width and depth that grows with sample size. The framework provided also offers potential for research into other DNN architectures and time-series applications.