 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Activation Function Normalization
Paper and Code
May 03, 2019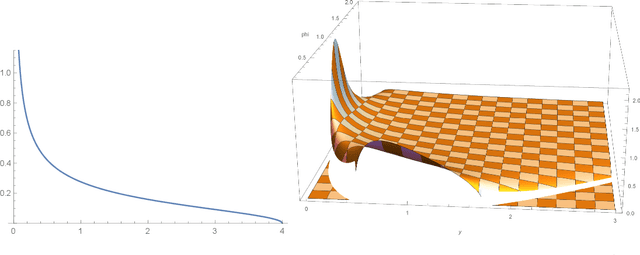
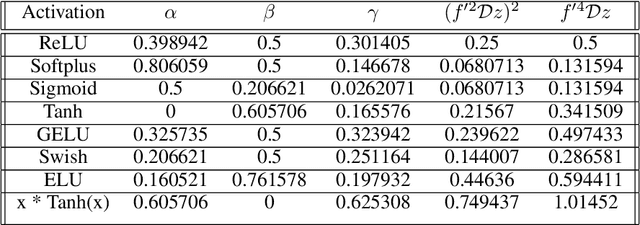
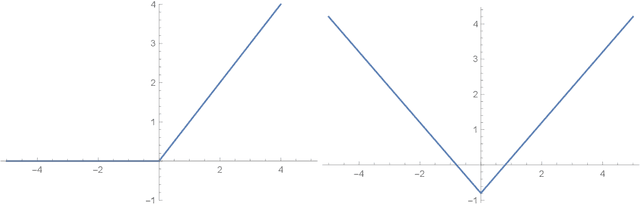
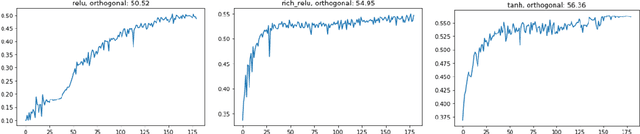
Recent seminal work at the intersection of deep neural networks practice and random matrix theory has linked the convergence speed and robustness of these networks with the combination of random weight initialization and nonlinear activation function in use. Building on those principles, we introduce a process to transform an existing activation function into another one with better properties. We term such transform \emph{static activation normalization}. More specifically we focus on this normalization applied to the ReLU unit, and show empirically that it significantly promotes convergence robustness, maximum training depth, and anytime performance. We verify these claims by examining empirical eigenvalue distributions of networks trained with those activations. Our static activation normalization provides a first step towards giving benefits similar in spirit to schemes like batch normalization, but without computational cost.