Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTANNIS: Low-Power Acceleration of Deep Neural Network Training Using Computational Storage
Paper and Code
Feb 19, 2020


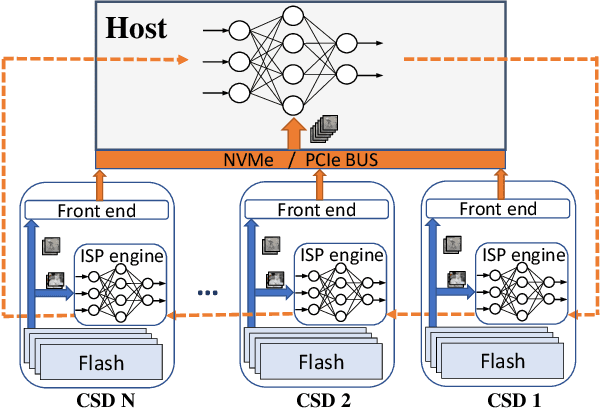
This paper proposes a framework for distributed, in-storage training of neural networks on clusters of computational storage devices. Such devices not only contain hardware accelerators but also eliminate data movement between the host and storage, resulting in both improved performance and power savings. More importantly, this in-storage processing style of training ensures that private data never leaves the storage while fully controlling the sharing of public data. Experimental results show up to 2.7x speedup and 69% reduction in energy consumption and no significant loss in accuracy.
View paper on