 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras
Paper and Code


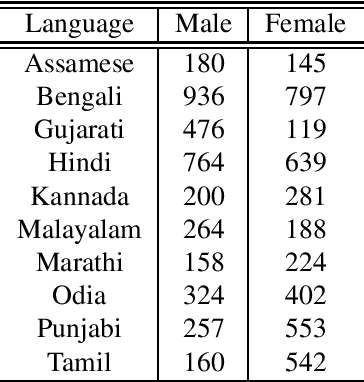
India is home to a multitude of languages of which 22 languages are recognised by the Indian Constitution as official. Building speech based applications for the Indian population is a difficult problem owing to limited data and the number of languages and accents to accommodate. To encourage the language technology community to build speech based applications in Indian languages, we are open sourcing SPRING-INX data which has about 2000 hours of legally sourced and manually transcribed speech data for ASR system building in Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Odia, Punjabi and Tamil. This endeavor is by SPRING Lab , Indian Institute of Technology Madras and is a part of National Language Translation Mission (NLTM), funded by the Indian Ministry of Electronics and Information Technology (MeitY), Government of India. We describe the data collection and data cleaning process along with the data statistics in this paper.