 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous Informal Speech Dataset for Punctuation Restoration
Paper and Code
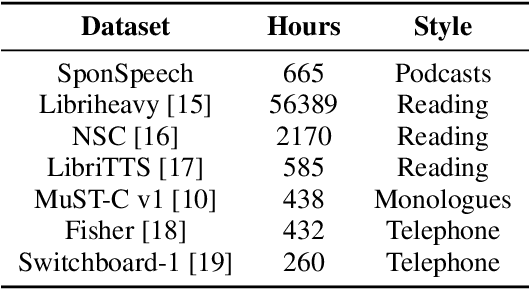

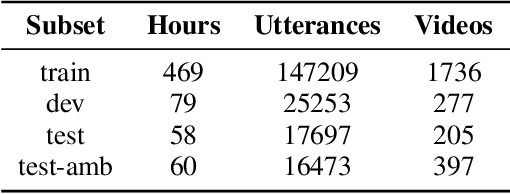
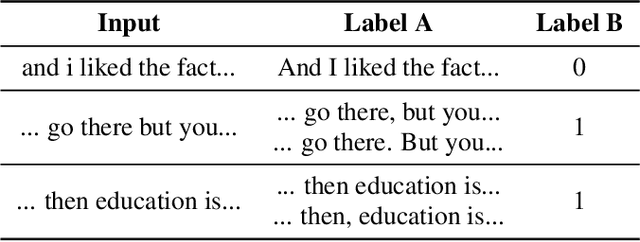
Presently, punctuation restoration models are evaluated almost solely on well-structured, scripted corpora. On the other hand, real-world ASR systems and post-processing pipelines typically apply towards spontaneous speech with significant irregularities, stutters, and deviations from perfect grammar. To address this discrepancy, we introduce SponSpeech, a punctuation restoration dataset derived from informal speech sources, which includes punctuation and casing information. In addition to publicly releasing the dataset, we contribute a filtering pipeline that can be used to generate more data. Our filtering pipeline examines the quality of both speech audio and transcription text. We also carefully construct a ``challenging" test set, aimed at evaluating models' ability to leverage audio information to predict otherwise grammatically ambiguous punctuation. SponSpeech is available at https://github.com/GitHubAccountAnonymous/PR, along with all code for dataset building and model runs.