 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRe: Boosting LLM Inference Throughput with Speculative Decoding
Paper and Code
Apr 08, 2025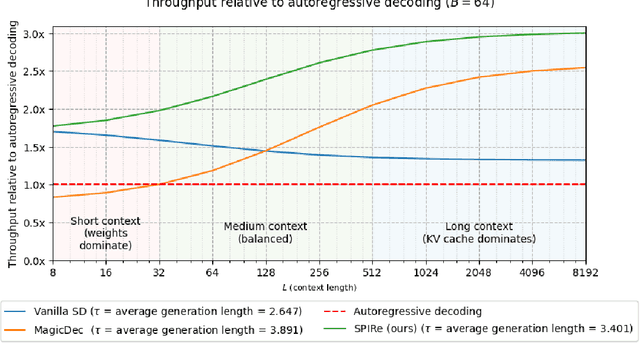
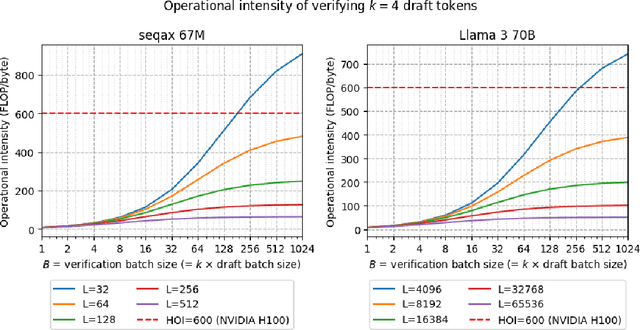
Speculative decoding (SD) has been shown to reduce the latency of autoregressive decoding (AD) by 2-3x for small batch sizes. However, increasing throughput and therefore reducing the cost per token requires decoding with large batch sizes. Recent work shows that SD can accelerate decoding with large batch sizes too if the context is sufficiently long and the draft model's KV cache is sparse. We introduce SPIRe, a draft model that combines static sparse attention, pruned initialization, and feedback memory to increase the modeled throughput of speculative decoding by over 100% compared to speculation with a much smaller draft model and by over 35% compared to the strong baseline of sparse self-speculation. Our approach is particularly effective when context lengths vary significantly across requests.