Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Denoising in the Waveform Domain with Self-Attention
Paper and Code
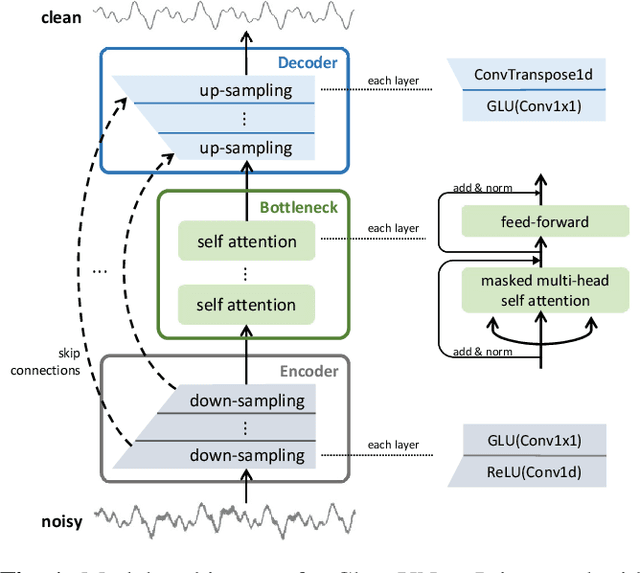
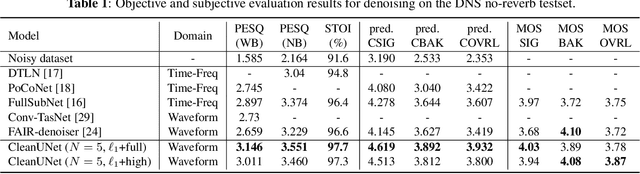
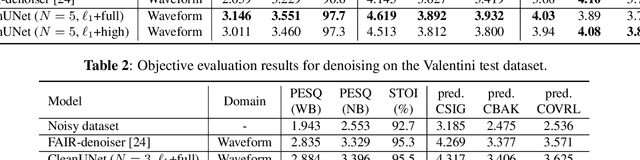
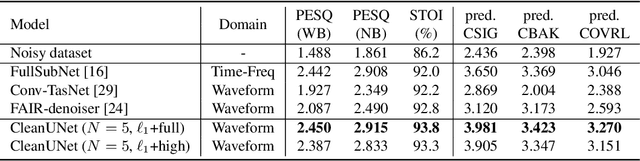
In this work, we present CleanUNet, a causal speech denoising model on the raw waveform. The proposed model is based on an encoder-decoder architecture combined with several self-attention blocks to refine its bottleneck representations, which is crucial to obtain good results. The model is optimized through a set of losses defined over both waveform and multi-resolution spectrograms. The proposed method outperforms the state-of-the-art models in terms of denoised speech quality from various objective and subjective evaluation metrics.
* ICASSP 2022
View paper on